
I keep picturing all these little kids playing some game in this big field of rye and all… And I’m standing on the edge of some crazy cliff. What I have to do, I have to catch everybody if they start to go over the cliff... That’s all I’d do all day. I’d just be the catcher in the rye and all.
J.D. Salinger <The Catcher in the Rye>
In the first half of "Shift Towards the Experience Era," we discussed the core features and limitations of current AI foundation models. We found that:
LLMs and reasoning give RL excellent generalization capabilities, forming a "general recipe" for model training that can quickly dominate almost any verifiable domain. These foundation models exhibit jagged capability patterns, with pockets of superintelligence—AI has learned virtually all human-produced text, and through analysis of the model's internal structure, we can consider that models have developed some kind of "understanding" of the world on paper. RL's generalization is achieved by training LLMs to reason with text (strictly speaking, this generalization is merely optimization of output distribution). Therefore, AI excels particularly at tasks where both input and output are text. However, probability distributions optimized by RL remain just that—probability distributions. Long-duration multi-step work accumulates error probabilities, and in some cases, models may not actually reason but instead might draw conclusions first and then find justifications. Moreover, AI lacks a real environment to test its understanding and cannot continuously improve it, because the parameters of foundation models are fixed for each release. In domains where environmental feedback is not easily converted to text, there's the additional problem of low "perception" efficiency regarding time, space, environment, etc. Multimodal models are improving this aspect, but overall lag behind. And models don't have consciousness, purpose, or motivation—in some sense, we might say RLHF gives models an "average" consciousness but not one tailorable for individual users.
Some of these issues can be improved by continuing to optimize along the general recipe, most notably the ability to work continuously for extended periods—recent GPT and Gemini models can already work continuously for over an hour to complete an IMO math problem. But some problems cannot be solved in foundation models under the existing paradigm, such as the inability to implement continuous learning. Even if "perception" efficiency improves, it cannot be remembered, and cognition of self/environment/purpose, or "consciousness," cannot be learned "after birth." From another perspective, everything the model can acquire after birth, including "understanding," "perception," and "consciousness," can only exist within the context window of each conversation. Having said that, compared to human intelligence, since this intelligence has a separation between software and hardware, their parameters and "memories" in context are indeed easier to store, copy and reload.
To solve these problems, model training must enter the age of experience, evolving from "learning from human data" to "learning from the experience in the real world."
Based on these understandings, in the second half, we'll examine AI applications in the age of experience.
Abundance and Scarcity in 2025
First, let's take a step back and try to understand the changes brought by AI. Alex Danco's series on scarcity and abundance presents a highly insightful framework for analyzing breakthrough technological innovations. The core concepts of this framework are:
- Technological Innovation and the "Red Queen's Dilemma": Breakthrough technological innovations often transform previously scarce resources or skills into abundant ones. However, this abundance frequently puts technology providers in a "Red Queen's Dilemma"—where they must keep running just to stay in the same place. The originators or owners of the technology don't always reap the highest returns. The true winners are often those who, after old resources and skills are no longer scarce, can control the newly emerging elements of scarcity.
- Demand-Side "Overserving" and "Underserving": User needs exist in layers. In all mature industries, there's a common problem where users are "overserved" at one level—paying premium prices for many features or services that provide little utility, Meanwhile, at the next level, users often face an "underserving" predicament—their genuine core needs at this level remain unmet,For example, the vast majority of us probably use only 10% or less of Office software features. Even mature software like Amazon retail or Google search still employs numerous talented engineers who continuously improve functions we rarely notice. Yet using spreadsheets for data analysis to validate our ideas remains challenging, especially when data isn't well-structured. Similarly, finding satisfactory products or planning a family vacation continues to be frustrating. If a new technology or product can simultaneously address both "overserving" and "underserving," it has the potential for explosive growth.
- Consumer Decision-Making and Market Structure in an Age of Abundance: When resources are scarce, consumer decision friction is extremely high, and people repeatedly weigh various factors, resulting in consumption decisions that roughly follow a normal distribution. However, when resource and skill supplies become abundant, the marginal cost of choice decreases, and consumption friction drops significantly. In most cases, people tend to "mindlessly" choose the default option, leading to a "winner-take-all" scenario. Only in highly niche or specialized demand scenarios will users actively seek products that precisely meet their specific requirements. This explains why markets exhibit a power-law distribution: top players dominate almost the entire market, while simultaneously there exists a long tail of suppliers, each with their own loyal user base. The most typical example is the respective ecological niches of Starbucks coffee and specialty coffee shops.
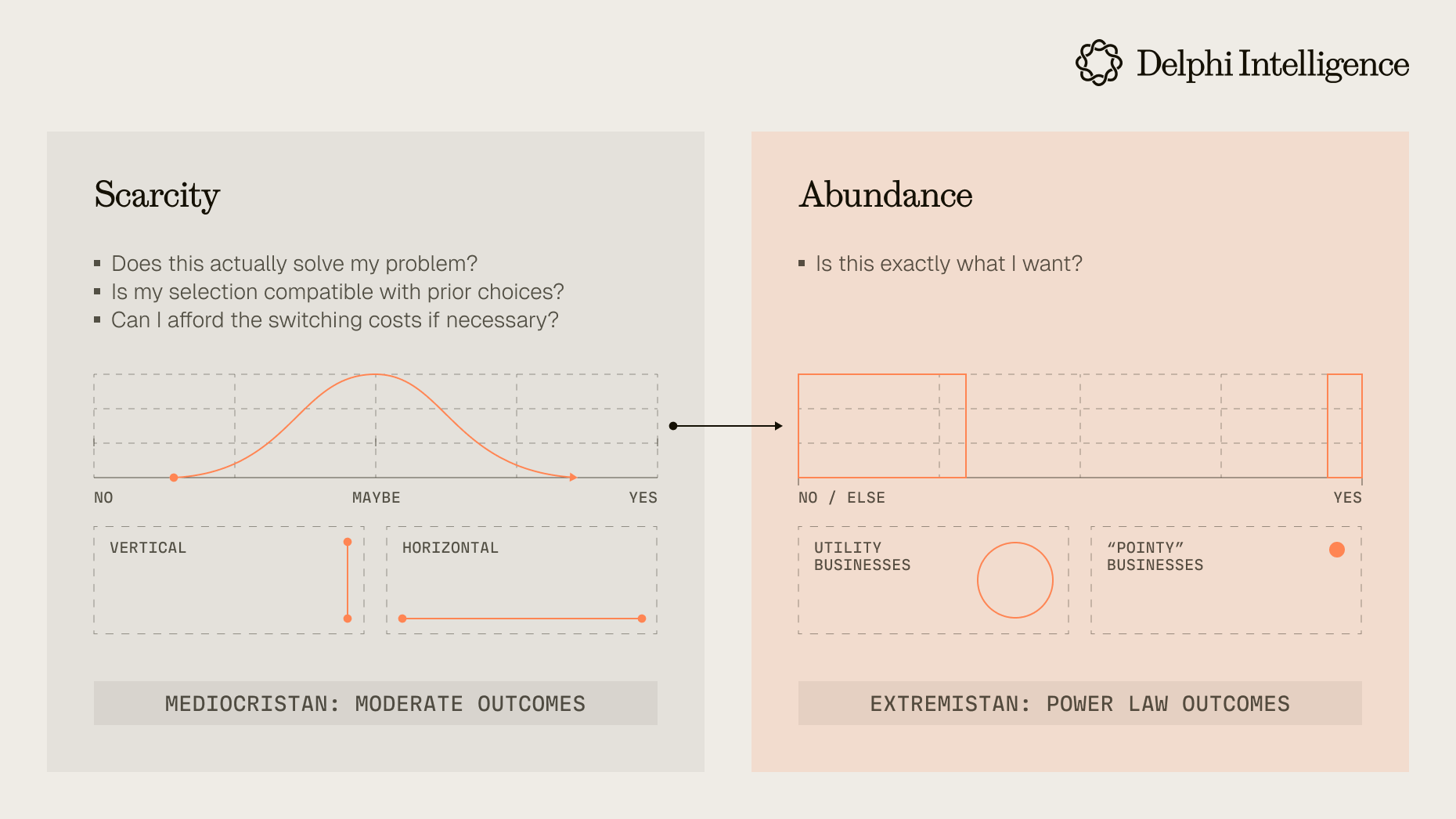
If we use this framework to examine the impact of AI, the new abundance is obvious. Sequoia provides an excellent description in AI Ascent 2024: Since the Industrial Revolution, human society has seen a continuous increase in food and goods supply with significant price decreases; however, service prices have consistently risen in line with average societal inflation rates. Although some services (such as the record and film industries) have achieved industrialization, numerous professional services like education, healthcare, coding, design, etc., remain difficult to scale. The fundamental reason is that professional services are distinctly non-standardized and extremely dependent on human expertise. The strength of LLM capabilities lies precisely in enabling these types of professional services—which primarily rely on information, especially textual information, as input and output—to have the potential for industrialized production.
The abundance of intelligence has been an ongoing process over the past two years. Elad Gil mentioned a "GPT Ladder" phenomenon: the success of applications depends on positioning in advance for soon-to-be-unlocked model capabilities. GPT-4 activated a batch of workflow applications, Claude 3.5 activated Cursor, Claude 3.7 activated Manus, with each leap in model capability creating new application opportunities. DeepResearch is another example—Google released this product first, but market reception was lukewarm until OpenAI released a product with the same name and features alongside their O3 model, which was hugely successful. Today, however, the emergence of the general recipe means this round of model training technology has begun to converge. General models can now earn IMO gold medals through reasoning ability alone. Intelligence is no longer the constraining factor, and we're truly entering an era of abundance.
Model companies have also recognized this. They're increasingly entering the application space, partly because model companies have entered a typical Red Queen's dilemma - simply release new model won’t gain them additional market share since your competitors are doing the same. The US market has OpenAI, Anthropic, Google, and xAI as first-tier players, with Meta trying very hard to catch up. Each is frantically investing in computing power and talent, with new SOTA models being born at an increasingly rapid pace, but new model launches no longer attract attention like rock concerts. On the other hand, for OpenAI, Sam Altman's vision is for AI to occupy a single-digit percentage of global GDP. The bottleneck for this KPI has shifted from model capability to AI technology penetration. The recent GPT-5 release provides an excellent case study. OpenAI likely didn't release the IMO gold medal-winning model in full strength for public use. Instead, this launch focused more impressively on lowering GPT's usage barriers and attracting developers rather than showcasing model intelligence (I've analyzed this in detail here). This indicates that OpenAI's focus has shifted toward encouraging more people to adopt GPT as their intelligence portal and preferred development platform, rather than pursuing AGI.
Software applications have evolved from standalone, to internet, then to mobile internet/SaaS/cloud computing, through repeated iterations of oversupply and undersupply. Before ChatGPT launching, most domains exhibit typical characteristics of oversupply: "winners" emerge with absolute market leadership. However, in various professional fields, converting human intent into tool commands remains a high-threshold task; Apps have also broken the interconnectivity of PC internet, forming information silos; while content supply has become overwhelming, with almost everyone entering recommendation-driven information cocoons. These factors have created an underserve of user needs at the next level. The abundance of intelligence brought by AI has begun to change all this - from lowering barriers (vibe coding), to breaking information silos (computer use), to handling information overload (deep research) - all hitting the intersection of overserve and underserve, which is why it’s growing in such a speed. But new aspects of overserve are gradually emerging:
- Too many model choices: before GPT5 releases, OpenAI has GPT series and O series, each with multiple versions; adding other vendors, users face severe choice paralysis
- Low differentiation among general-purpose models: For common generative or reasoning tasks, current model capabilities are more than adequate. Ordinary users can't distinguish between Sonnet and Opus, nor can they tell how Claude and GPT differ. After OpenAI recently discontinued GPT-4o following the GPT-5 release, many users reported that GPT-5 doesn't perform as well as GPT-4o. This is less a comparison of intelligence and more a reflection of users having grown accustomed to GPT-4o's output style. The main driver for users choosing between $20 or $200 monthly subscriptions is whether they heavily rely on DeepResearch or Claude Code
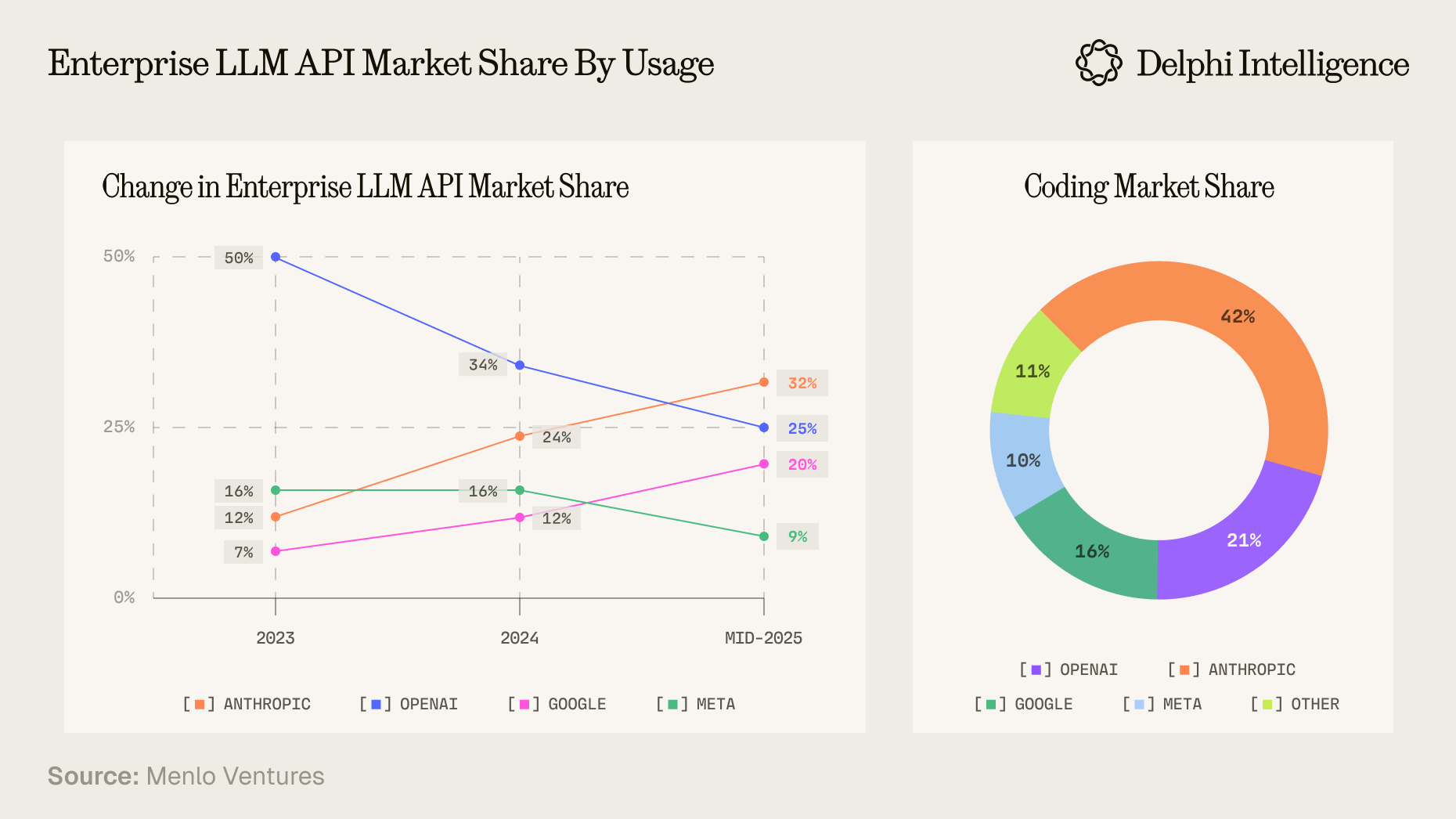
- Concentration trends emerging at the top: Compared to two years ago, first-tier model companies have actually grown closer in capability, but ChatGPT is the only ChatBot with a DAU/MAU ratio reaching 20%, while Bing (also based on ChatGPT) and China's DeepSeek are the other two reaching 15%, the rest haven't reached 10% - we're beginning to see the winner-takes-all trend in Danco's theory. Leaders in other specialized areas are also emerging: Claude is preferred for coding and APIs which generates majority(60~70%) of Anthropic revenues, Gemini API is chosen for cost sensitivity, and so on.
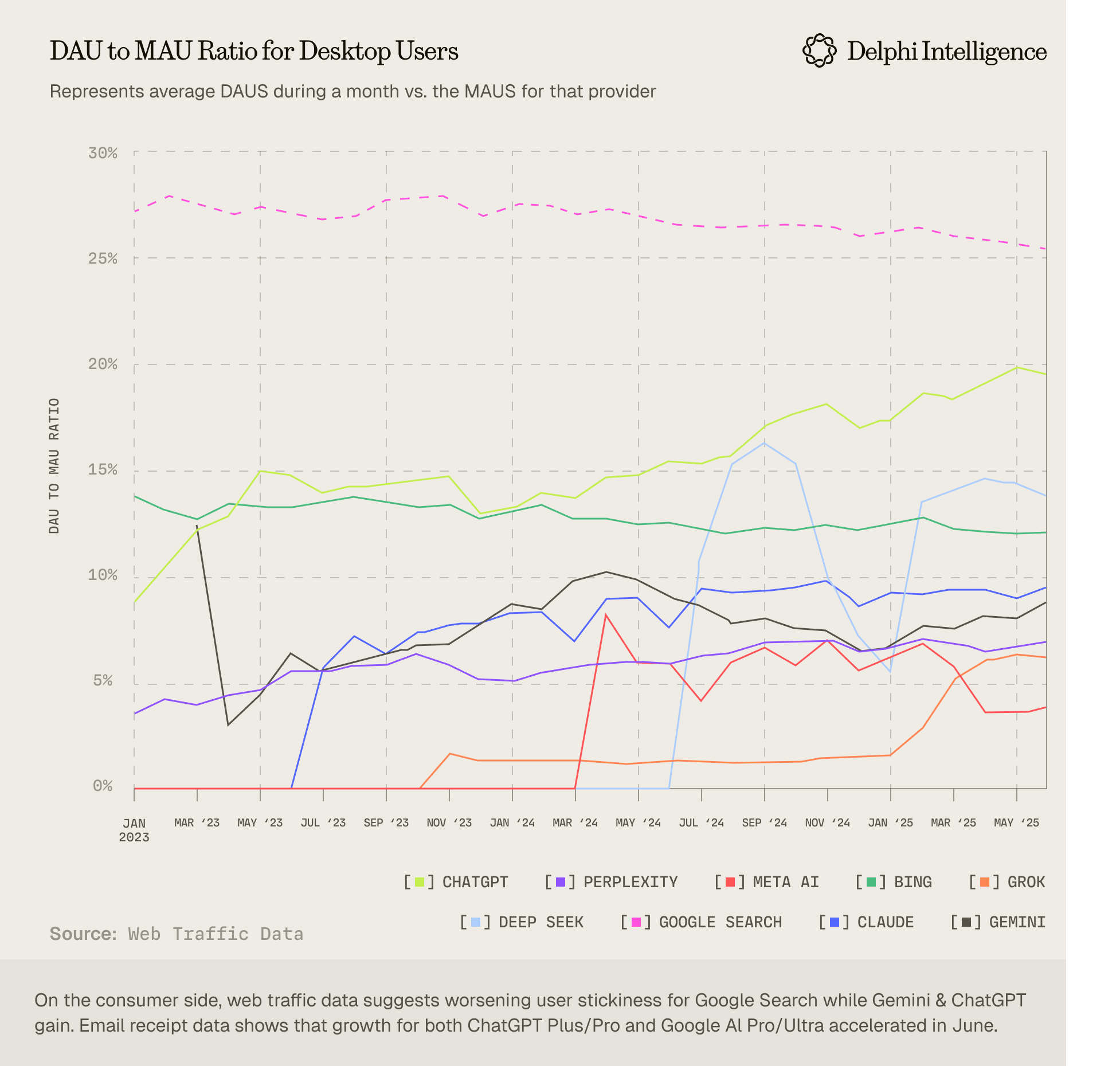
On the other hand, the challenge is the persistently high usage barriers. Anthropic CPO Mike Krieger noted that today's Claude still can't match the user-friendliness of Instagram, his previous product: most users struggle to effectively express their needs, hallucinations continue to frustrate users, and ChatGPT's memory features haven't adequately solved the context acquisition problem. Even OpenAI Deep Research(ODR), the best in its class, fails to generate in-depth reports that truly meet user requests. I've observed sophisticated users employing complex calibration processes with ODR, following approaches like:
- First, having ODR list 100 key opinion leaders in a specific field along with their main works
- Users reading these works and commenting on valuable sections
- Having AI generate a user profile and preferences based on these comments
- Finally, submitting this user profile as part of the prompt to ODR
This elaborate process barely produces the in-depth professional reports users actually want. In essence, O3 possesses the capability, but requires users to manually perform a complex "alignment" process to access it.
So it's not surprising that many AI applications aren't positioned for professional users. And a recent article by Foundation Capital also clearly points out: Competition has shifted from "who has stronger product features" to "who can more deeply transform AI capabilities into actual business outcomes for customers"
Consciousness Alignment, Then Let AI Run
context, not control
Netflix's mantras
So what kind of AI applications do we need? Perhaps this begins with understanding how users can effectively harness abundant intelligence.
Jigang Li, a prominent Chinese internet personality known for sharing advanced prompt techniques, uses human-to-human communication patterns as an analogy for human-AI collaboration. He argues that prompting isn't writing or programming, but a form of expression—effective prompts create a shared creative space for both human and AI intelligence. The "Johari Window," traditionally used to analyze human communication strategies, can be applied to human-AI interaction scenarios. Across its four quadrants, prompting strategies should vary accordingly. In the Open quadrant—where both I(self) and AI(others) possess the same knowledge—concise requirements work best, as excessive elaboration only constrains the AI's potential. For the Hidden quadrant, where the I(self) know something the AI(others) doesn't, detailed explanations of background, structure, and specifics enable the AI to express itself effectively. As AI capabilities grow, the X-axis of the Johari Window continuously shifts downward, meaning the unknown areas for AI keep shrinking, while the Y-axis varies from person to person.

In fact, regarding public domain knowledge, AI has likely surpassed humans, making the Blind quadrant significantly larger than the Open quadrant. This explains why AI works so effectively in areas unfamiliar to users, with breadth of coverage well addressed. However, as problem-solving becomes deeper and more specific, it increasingly shifts into the Hidden quadrant. Here, AI requires comprehensive context to function effectively, with the most crucial context being the users themselves—their environment and intentions. This isn't merely information the model lacks but represents a fundamental limitation of its capabilities. This necessitates "consciousness alignment" with the user. Let me define this concept:
Consciousness alignment refers to an AI application's process to establish synchronized self-awareness, situational perception, and goal alignment with the user within the current dialogue context. This enables AI to:
- Understand the user (what kind of person am I)
- Understand the user's current intentions (what goals do I want to achieve, what is my purpose)
- Understand the user's environment (what environment am I in, what is the gap between me and completing my goal, what resources and capabilities do I have, what am I missing)
- Understand the user's expectations (what do I want you to help me with)
- Intervene at appropriate times in appropriate ways (synchronous assistance or asynchronous execution)
Consciousness alignment compensates for the model's inherent limitations in environmental perception, continuous learning, and personalization, and is key to transforming "averaged consciousness" into "personalized experience." This alignment must consider constraints including user will, privacy, security, compliance, cost, and complexity. Achieving appropriate consciousness alignment for the current task will be the most important factor in fulfilling AI's potential
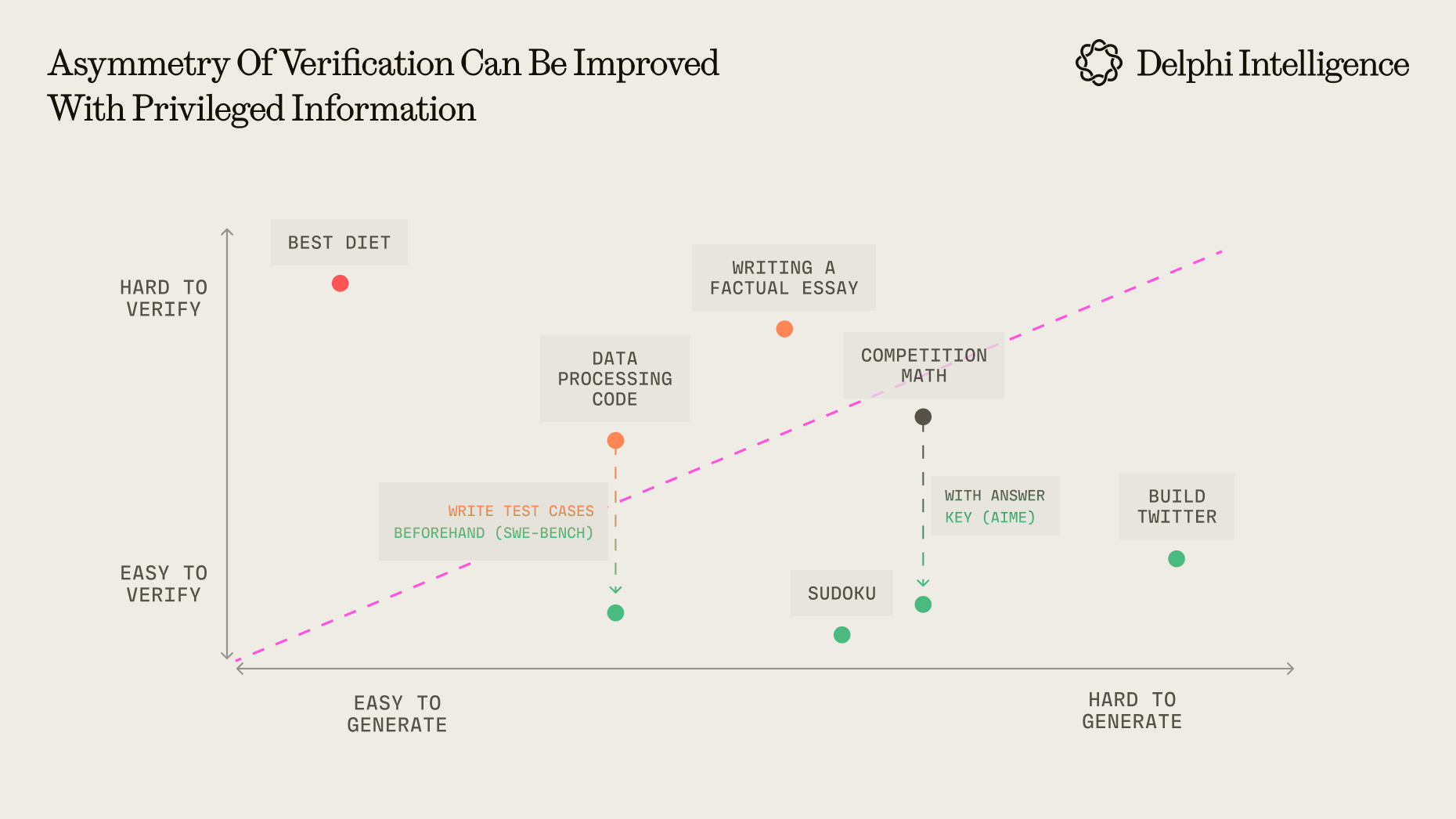
Another key point is creating an environment that allows AI to run safely. AI's randomness is an established fact, whether it's truly engaging in reasoning or just optimized pattern matching is also debated; while alignment for safety is a necessary cost, further restricting AI from a functional perspective becomes counterproductive. Forcing AI into a specific step of an existing workflow to improve local efficiency often means controlling its output to meet upstream and downstream standards, or extensively interfering with its work in the open quadrant. This limits AI's capabilities, turning its randomness into a problem rather than an opportunity—like asking a rocket scientist to tighten screws on an assembly line. Conversely, AI has incomparable advantages over humans: copying model parameters or reloading context through RAG is far easier than training a college graduate to become an industry expert from scratch. To maximize AI's potential, we should embrace its randomness and fully leverage its replicable intelligence and context. This often requires changing existing professional service workflows, with the key being: provide sufficient context, don't obsess over precision in a single attempt, make multiple attempts, and ensure proper verification. As Sequoia says, "embrace randomness," attempt multiple approaches in parallel with both a leader's and explorer's mindset, and establish good filtering rules rather than excessively pursuing precision in a single execution. This approach heavily relies on verification rules to ensure correctness and isn't suitable for all situations, but it's particularly effective for scenarios that fit Jason Wei's asymmetry of verification. The guess-and-check approach isn't just valuable during model training; it's equally powerful for optimizing results during inference.
Given the above insights on leveraging AI intelligence, the path forward for applications becomes clearer:
First, expanding the open and blind quadrant provides the most fundamental competitive advantage, though large model providers are already focused here. These companies are enhancing general models while strategically entering specialized fields through partnerships—Anthropic launching Claude Financial, OpenAI investing in Harvey, and DeepMind continuously developing AI4S. Nevertheless, applications should seize opportunities to build advantages in the Open area whenever possible. SlingshotAI exemplifies this approach: they interviewed over 100 therapists before developing their psychotherapy assistant Ash, partnered with multiple behavioral health organizations to create the industry's largest behavioral health dataset covering diverse treatment approaches, and ultimately built the first psychology-specific foundation model. This "Model As Product" strategy represents the optimal choice for AI services in vertical fields.
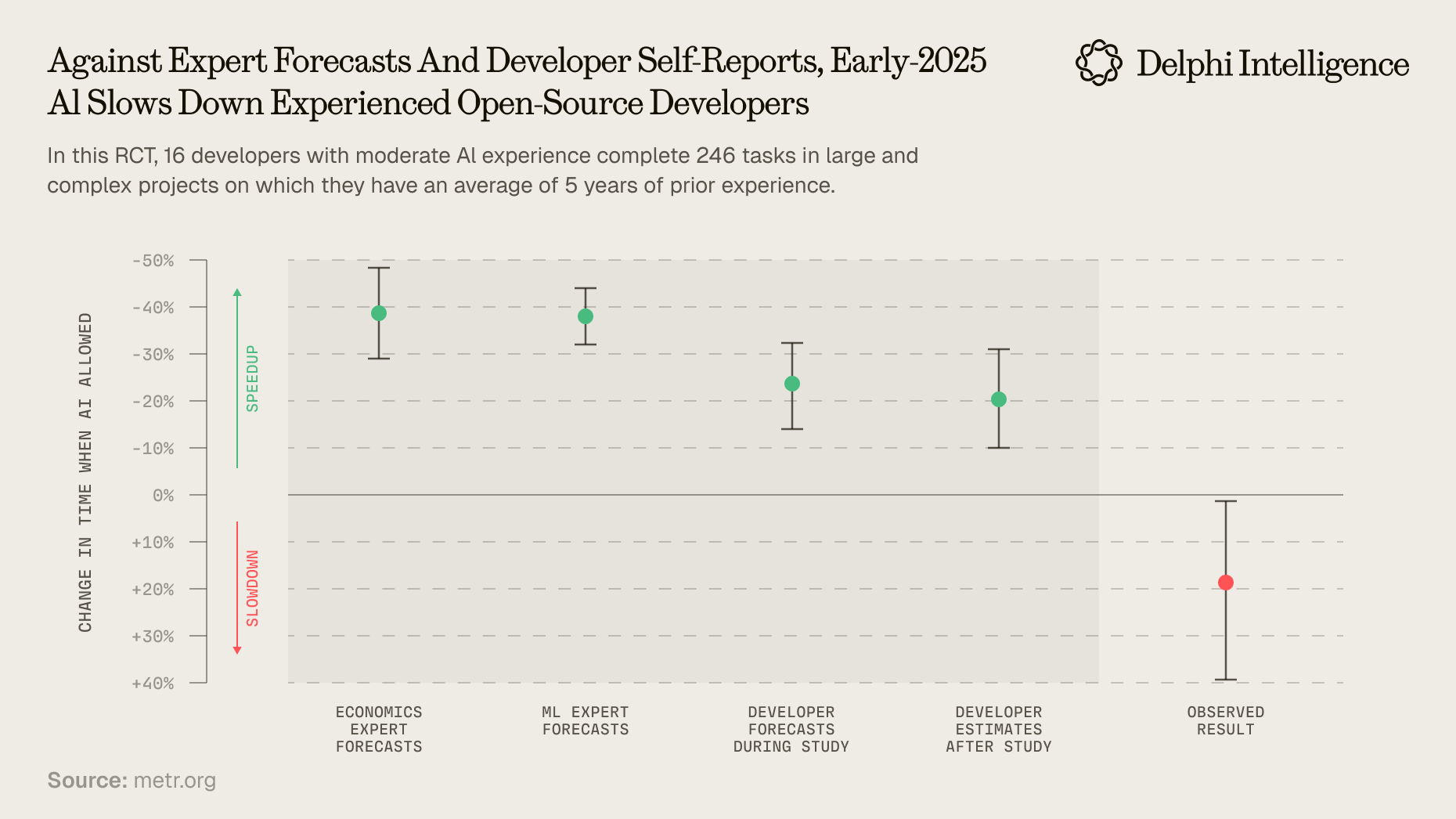
Secondly, guide users to work in the hidden quadrant by aligning consciousness with AI. Applications need to effectively guide users to provide high-quality information in this quadrant, align awareness with AI, and reduce control in the open and blind quadrants. Vibe Coding adoption illustrates this principle well. Product managers generally report better experiences with Vibe Coding than programmers do. This isn't coincidental. METR's research shows that AI coding actually slows developers down by an average of 19%. A key reason is that product managers have extensive experience structuring user needs and communicating with engineering teams—effectively working in the hidden quadrant. In contrast, programmers tend to over-communicate with AI in the open quadrant. The METR report also reveals that AI programming is less helpful in areas where programmers are more familiar. This relates partly to AI's relative capabilities, but also because programmers have clear but unstated expectations in these fields. As reason 5 states: AI cannot leverage the important implicit knowledge or context accumulated by developers. For ordinary users, articulating high-quality needs remains challenging. They benefit from guided demand analysis to lower this threshold.

Third, innovate the workflow to unleash AI: MidJourney's four-choice model was the earliest indicator of this approach—complete task blocks, parallel execution, and manual filtering. Today, leading AI users have adopted entirely different workflows: Devin's founder Scott Wu revealed that each Devin employee works with 5 Devin instances simultaneously. Anthropic reported that Claude has contributed more than 90% of their code. A key factor enabling this shift is Claude Code's command line interface, which is exceptionally easy to integrate so that it can be executed in various ways. It can connect with other tools through MCP and can be integrated by other tools in its headless mode. This integration functions similarly to Unix commands connected through pipelines, creating countless usage scenarios far beyond software development. Anthropic's official publication How Anthropic teams Use Claude Code provides compelling evidence that "Claude Code is All You Need." The document reveals that not only product and development teams use it throughout the software process, but legal, marketing, financial, and other departments have also deeply integrated Claude Code. Its application extends well beyond technical domains—they describe its target users as "anyone who can describe a problem into someone who can build a solution." Usage methods are remarkably diverse, with many teams adopting approaches like "never modifying, start over whenever not happy." Their final summary reinforces our insights from the Johari window analysis: "Claude Code works best when you focus on the human workflows that it can augment. The most successful teams treat Claude Code as a thought partner rather than a code generator."
Fourth, create new interactions: the command line is too hardcore for most users, and popular applications need more friendly interactive interfaces. The current chatbot form resembles the command line shell of an LLM OS—our mainstream AI interaction remains in the DOS era. When we view applications as containers, their purpose is to help users naturally align their perception and consciousness with AI, which requires interactive innovation. This is relatively easier in specific scenarios. For example, in Granola's earliest version (https://www.granola.ai/blog/announcement), they already proposed encouraging users to take meeting notes "to point the AI at what's important." This creates a shared perceptual field where AI and humans collaborate in the conference environment, naturally achieving human-computer alignment. More general AI applications will eventually upgrade from "DOS interface" to "Windows." We can expect UI and content to evolve in a generative rather than predefined direction. As code generation efficiency improves, AI applications will generate and render GUIs in real time to guide user operations.
Fifth: Selling a Worldview to Build Momentum: For applications, gaining initial momentum is crucial. However, momentum-building strategies have evolved. During the GPT Ladder period, success came from positioning ahead of new model releases, preparing features in advance, and launching immediately when models dropped. Now, as intelligence becomes abundant and effective use becomes the bottleneck, "build in public" has emerged as the superior strategy. This approach involves sharing the team's product philosophy and AI usage best practices, attracting like-minded users early—essentially functioning as a software "kickstarter." SWAN AI exemplifies this approach perfectly. This AI-driven sales automation company acquired 80 paying customers approaching $1M AAR in just 9 weeks with only a 3-person team. Their customer acquisition relied entirely on LinkedIn, where founder Amos posts three times weekly, generating 1.5 million views monthly. His content focuses on spreading the "autonomous enterprise" concept, with users first connecting with this philosophy, making actual product sales almost a natural outcome.
Sixth, Build Continuous Learning Harnesses: While the strategies above offer temporary advantages, they can't prevent competitors from catching up or shield against foundation model providers' asymmetric advantages. Long-term user retention depends on implementing ongoing learning capabilities on top of the model. When MidJourney launched, many believed user feedback would create a data flywheel for model improvements—this proved unviable. However, using interaction data to align with user intent works remarkably well, creating an experience that becomes smoother with use. Since the underlying model parameters remain fixed, this advantage can only be built by applications that directly interface with users, creating harnesses around the model. In a recent YC interview, Perplexity CEO Aravind Srinivas plainly stated that "all user chat histories are important future assets." Following NotebookLM's lead, many applications now focus on "Content For One," making personalization their core feature. ParticleNews helps readers understand news through their unique lens, while Huxe boldly promises "The most personalized content on the internet: made only for you." These products integrate information based on user preferences, creating experiences more personalized and stickier than even TikTok's recommendation engine. While previous approaches help users leverage AI capabilities, this user growth must ultimately feed into continuous learning that supports consciousness alignment for future interactions. Only by addressing the model's structural limitations—rather than temporary capability gaps—can applications resist the threat of model upgrades and upward erosion of application space.
Last but not least, creator communities: Each generation of new technology and tools spawns new creator communities, forming network effects with end users. The most famous historical example is undoubtedly Chrome, which managed to overtake Windows' bundled IE monopoly largely because it firmly captured the developer community. We can say that technologies like the V8 engine, HTML5, and Node.js gave birth to the frontend developer community. This extends beyond just software engineers—from bloggers and YouTubers to TikTokers, content creator communities follow the same pattern. The first emerging creator group born in the AI era is undoubtedly the Vibe Coder. How to capture this group will be a fascinating topic, and we might see very different ecosystems emerge here, with one possibility being what Andrej Karpathy calls bacterial code:
.png)
To conclude this section, let's examine SourceGraph's Ampcode as a case study. Its product philosophy embodies many of the concepts we've discussed:
- They share their journey openly through multiple blog posts and podcasts, documenting new insights and product philosophies developed during Ampcode's creation
- They identify token cost as the primary bottleneck in AI work, opting to use only the strongest models with no user choice and no limits on token usage
- They prioritize feedback loops, rejecting the inefficient prompt-generate-manual fix approach in favor of real-time compiler/test feedback that enables models to self-correct continuously, similar to humans
- They center human-AI collaboration on "giving the model what it needs" rather than imposing artificial constraints. Their approach encourages users to abandon micromanagement and instead guide AI as they would a senior engineer: providing goals, constraints, key context, establishing feedback loops and guardrails, then letting AI work autonomously
- They advocate for toolset evolution, believing AI needs carefully selected, moderately abstracted tools—shifting from static code hosting like GitHub to conversation/intent/prompt-centered collaborations, even adapting codebases to AI rather than the reverse
- They implement sub-agents focused on single tasks to maintain context focus while enabling parallel execution
After implementing these approaches that "cede control" to AI, SourceGraph engineers reported in a recent interview that large models' reasoning and autonomy capabilities were dramatically enhanced. The models began working like senior engineers who "persist with problems," trying various methods until finding solutions, rather than behaving like clumsy, uncooperative "interns." The results were immediate—after its May launch, the product garnered significant attention from the software community, with the Every podcast rating it as the only S-tier coding agent alongside Claude Code.

From Ampcode's example, we can observe that models are absolutely not products. "Model as product" should be understood as an approach to build products by expanding the model's Open quadrant—compressing domain knowledge, business capabilities, and workflows into the model through post-training methods as a typical example. However, the model itself isn't sufficient to create a good product. You need to distill best practices into your product and guide users toward consciousness alignment with the model. Only then can you truly unleash the model's potential.
From Personnel to AI-First Organizations
We shape our tools and thereafter our tools shape us
Marshall McLuhan
Extending AI applications beyond individual professional users brings us to professional service institutions and large enterprises. Guided by the twin principles of "consciousness alignment" and "letting AI run," these organizations will undergo profound transformation. This evolution will birth an entirely new business ecosystem with countless opportunities.
- Professional Service Firms
AI's impact on professional services, like Vibe Coding's effect on software development, is transitioning from "selling tools" to "selling outcomes." In the legal field, Harvey represents the mainstream path for AI legal tools—empowering law firms and optimizing existing processes. Crosby, however, has chosen a more radical approach by directly reconstructing a law firm using AI+human experts.
Crosby's AI agents handle standardized, repetitive contract reviews, while top lawyers focus on complex judgments and strategic decisions. This collaborative relationship allows clients to receive professional legal advice within an hour. From a technical perspective, Crosby has built an "API for human protocols," transforming personalized contract negotiation into services accessible through a technical interface, with lawyers in the loop ensuring safety and compliance.
Furthermore, Crosby has integrated continuous learning throughout their service process. They establish a client-specific knowledge base that becomes increasingly customized by incorporating client preferences—embodying a form of "consciousness alignment."
Crosby's business model also differs significantly from traditional approaches. While conventional law firms bill by the hour and AI tool companies typically use fixed subscriptions, Crosby operates as "law-as-a-service": charging based on contract review volume or outcomes, directly linking payment to the value clients receive.
Crosby's team and customer is also representative, with approximately 19 employees, mainly composed of lawyers from law schools and engineers who almost all have founder backgrounds. Founder Ryan Daniels has served as chief legal counsel for many startups. Their clients are mostly tech industry startups.
Crosby's case illustrates the possibility of an AI-first professional service firm: aligning top industry experts' capabilities and client profile/intentions with AI, establishing an environment for AI-expert collaboration that unleashes AI's potential, satisfying client trust and regulatory compliance requirements through human-in-the-loop approaches and licensed practice according to industry standards, serving similarly AI-first, like-minded clients, and so on.
Besides this, there's another model: AI roll-up, which transforms traditional professional service firms through acquisitions, including Elad Gil, Thrive, and Khosla among many actively participating VCs. Their strategy: first incubate a new entity, then acquire highly manual/minimally digitized traditional service businesses, rapidly embed AI-native processes, improve profits to generate cash flow, then continue acquiring to expand scale
These three models—Harvey, Crosby, and Roll-up —may gradually merge as they develop. This might be the future of the $6 trillion professional services market.
- Enterprises
If we consider AI as a collaborator, studying human organizational theories can offer valuable insights for human-AI partnerships. Modern enterprise management theory has evolved alongside technological development, with significant focus on information flow and feedback mechanisms. Exemplary organizational practices from the U.S. military's Team of Teams, Netflix's freedom and responsibility, and Ray Dalio's "Principles" all share core values: honesty, transparency, accountability, feedback, and high performance. Team of Teams emphasizes shared context and distributed decision-making authority; Netflix promotes individual freedom and responsibility (their "only hire adults" philosophy); while Dalio champions "idea meritocracy" through a sophisticated "credibility-weighted voting" decision-making system.
AI Agents—collaborators with strong comprehension abilities but inherent randomness, limited perception, and no consciousness—can be deployed at scale with minimal cost, inevitably transforming enterprise organizational structures.
As with previous technological revolutions, the greatest challenge in enterprise AI adoption isn't the technology itself but the organizational and mindset transformation required. Current AI-enhanced Software-as-a-Service solutions merely optimize existing workflows—a transitional approach that won't generate substantial growth in the AI era.
Instead, new organizational forms based on AI-human collaboration may include:
- Code as labor rather than asset: Traditional software development treats code as accumulated assets requiring long-term maintenance. In the AI era, code functions more as on-demand labor that can be summoned when needed
- Dynamic generation and optimization of processes: Enterprise management processes no longer need complete predefinition; AI can dynamically create optimal processes tailored to specific situations
- Guardrailed "sandbox" environments: Similar to the "shared information, empowered execution" concept in Team of Teams—when each node understands overall goals and current context, it can make optimal decisions independently. For safety and compliance reasons, humans remain essential as ultimate guardrails, comparable to how virtual machines create secure sandboxes in computing
- Business models shifting from seat-based pricing to outcome-based pricing
Organizations that embrace AI at the structural level earliest will gain asymmetric competitive advantages. This isn't merely about adopting AI tools but reimagining the organization itself—how to achieve "consciousness alignment" between enterprise and AI, enabling AI to fully execute, receive feedback, and continuously improve within a guardrailed sandbox environment...
Conclusion
AI models built on LLM+RL are jagged intelligences—possessing intensive knowledge and sometimes strong comprehension, but inherently random, weak in perception, and lacking consciousness. Foundation models are entering the experience era, with AI applications built on them following suit. This paradigm has ushered in an era of abundant intelligence where the new scarcity lies in unleashing AI's full potential while maintaining safety and reliability. This shift demands a fundamental rethinking of our approach: whether for individuals, professional firms, or enterprises, working with AI resembles human collaboration but with crucial distinctions. We must align consciousness, grant autonomy, verify outputs, provide continuous feedback, and enable constant improvement. Welcome to the thrilling new AI experience era.









.png)
