
(And who will own them…)
Almost annually now, it seems the baton in the race for superintelligence is passed to a new pole in the tent. Compute, data, and energy: two sprint ahead, one forms the bottleneck. Depending on the location of the lag, the spice must flow.
In size.
With Grok 4's release, it's fairly clear we have not hit a definitive "wall". The bitter lesson remains in tact. The show goes on.
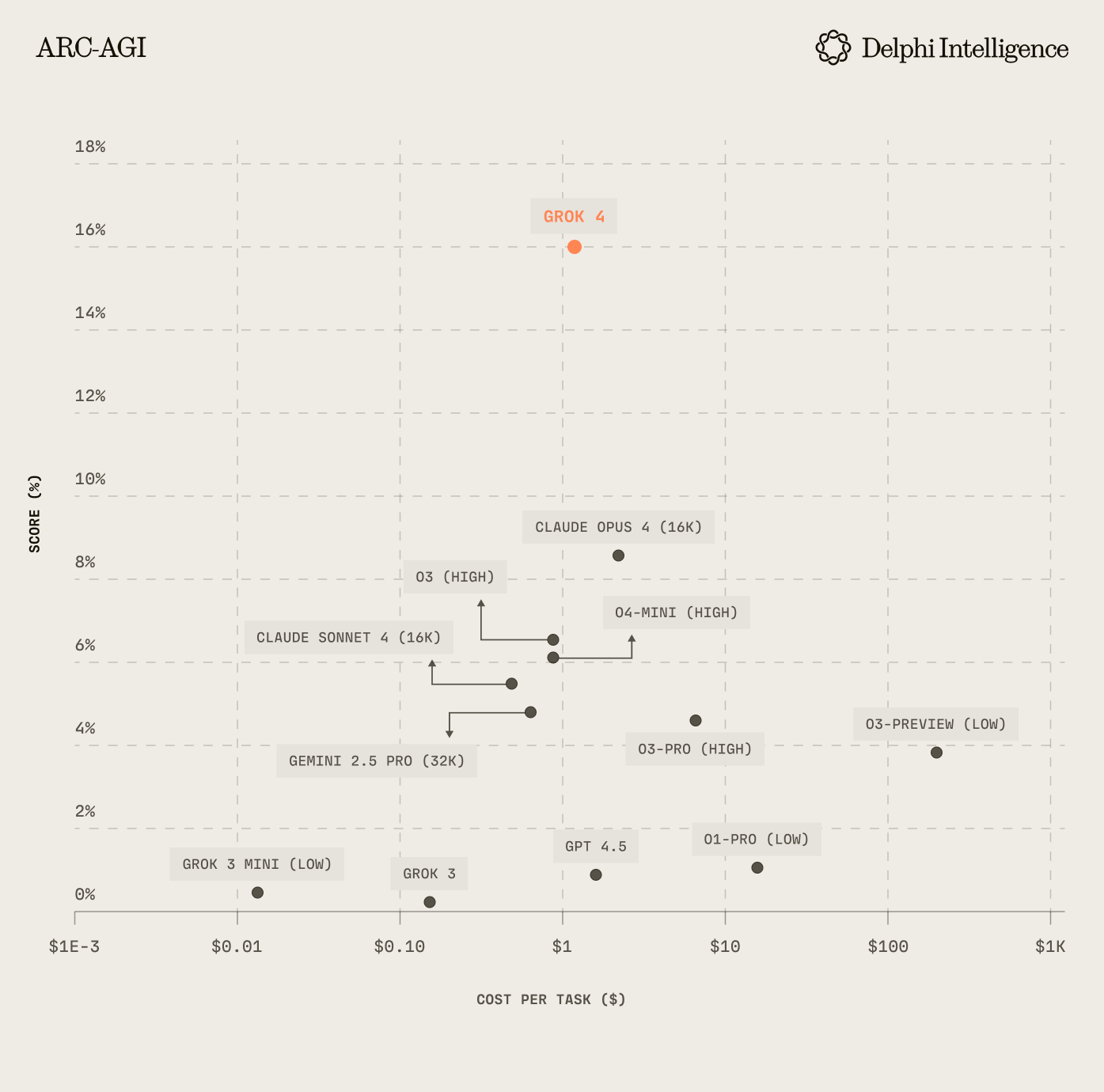
After earlier spotlights on GPU and energy shortages, the conversation (and ensuing dollars) have shifted to data. Meta's US$29b acqui-hire of Alex Wang and co from Scale AI is emblematic of this shift. Label Box CEO Mashu Sharma confirms all major labs are now spending >US$1b annually on data with budgets rising quickly.
It's not hard to understand why:
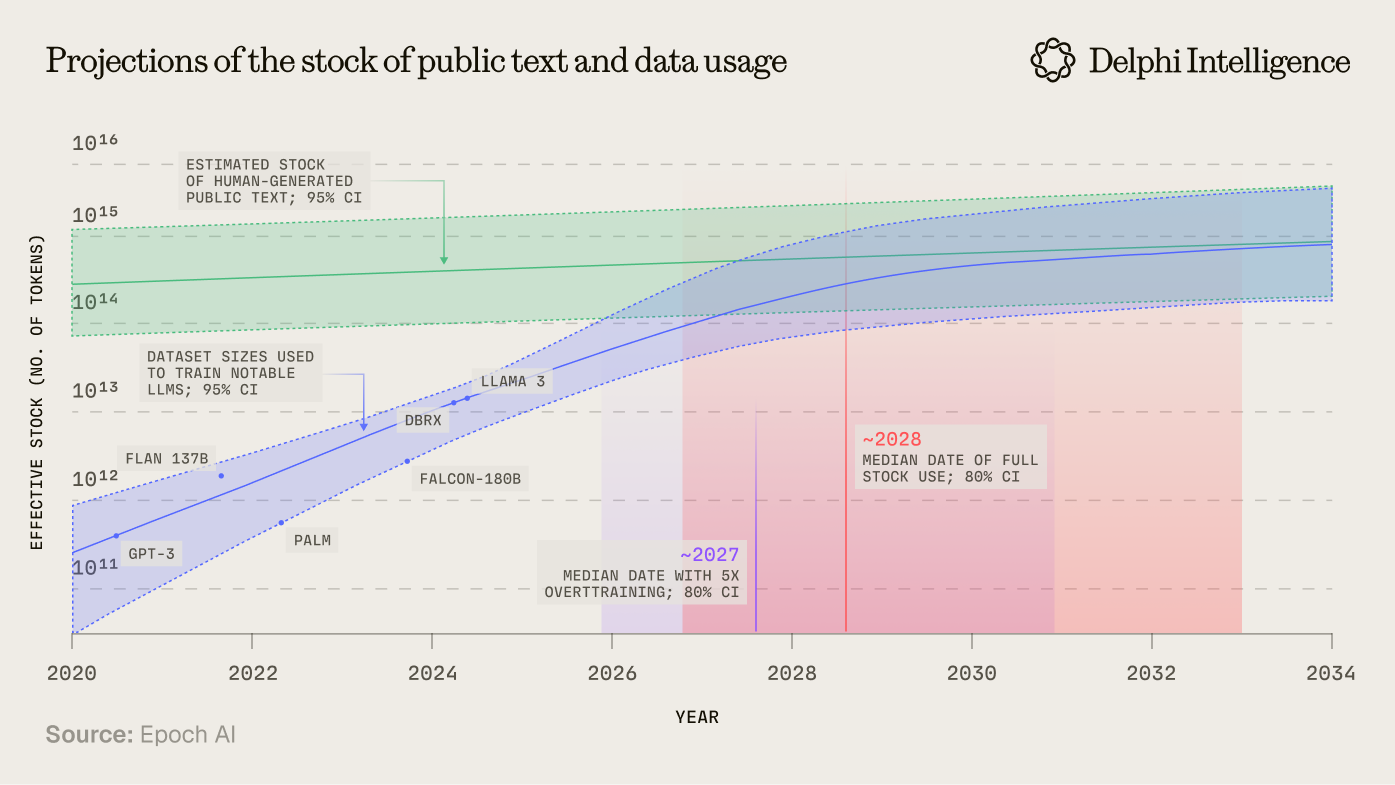
This increase in spend is anchored by a shift from the pre-training to the post-training paradigm. Instead of scrapping the public internet for generalized intelligence, post-training involves instilling specialized knowledge from particular domains.
Grok 4's relative breakdown between pre and post-training is a sign of how rapidly this shift has occurred:
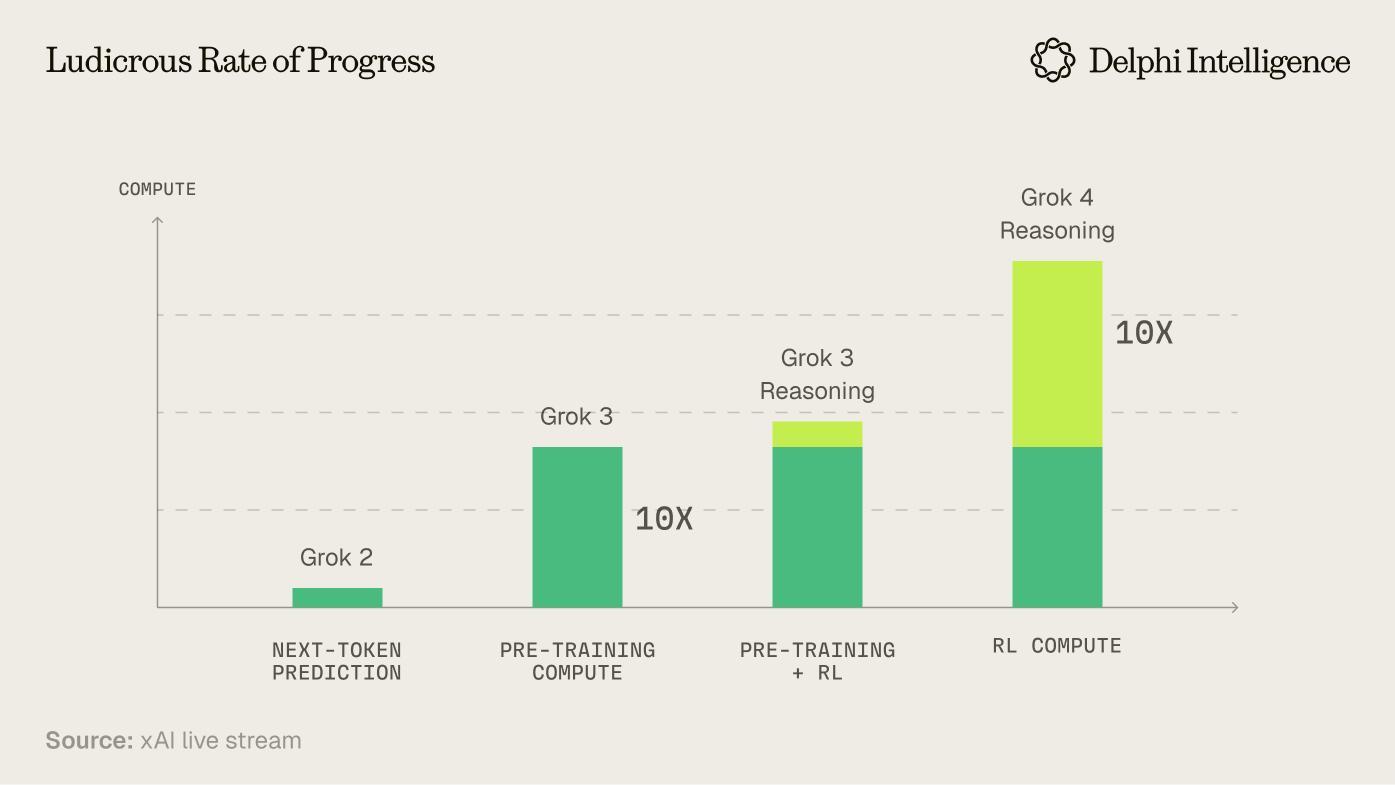
This paradigm shift has driven the revenue and valuation inflections within "Data Foundries" like Scale AI, Surge, Handshake, Mercor and others. These organizations specialize in crafting data pipelines, building the tools to manage them efficiently, and sourcing the increasingly high-end talent needed to guide synthetic intelligence in advanced domains*.*
The models are hungry.

The evolution of the type of human feedback has been rapid: climbing the ladder of expertise from low-wage labelling and annotation to paying PhD talent >US$250k per year.
But given this pace of progress and the promise of "pure RL" the natural question becomes: how long will we need the humans?
Answering this question requires speculation as to the timelines and most likely paths to AGI and beyond: traversing the current state of post-training to the holy grail of all-encompassing world models.
A journey which ends in what is perhaps an even more interesting question: Who will own them?
RL and Humanity: A Waltz
The value and demand for data is intricately tied to how post-training evolves and what techniques prove most effective in crafting usable synthetic intelligences for human tasks. There is a clear shift underway towards more reasoning in models, more test-time-compute, and more high-quality, task specific data.
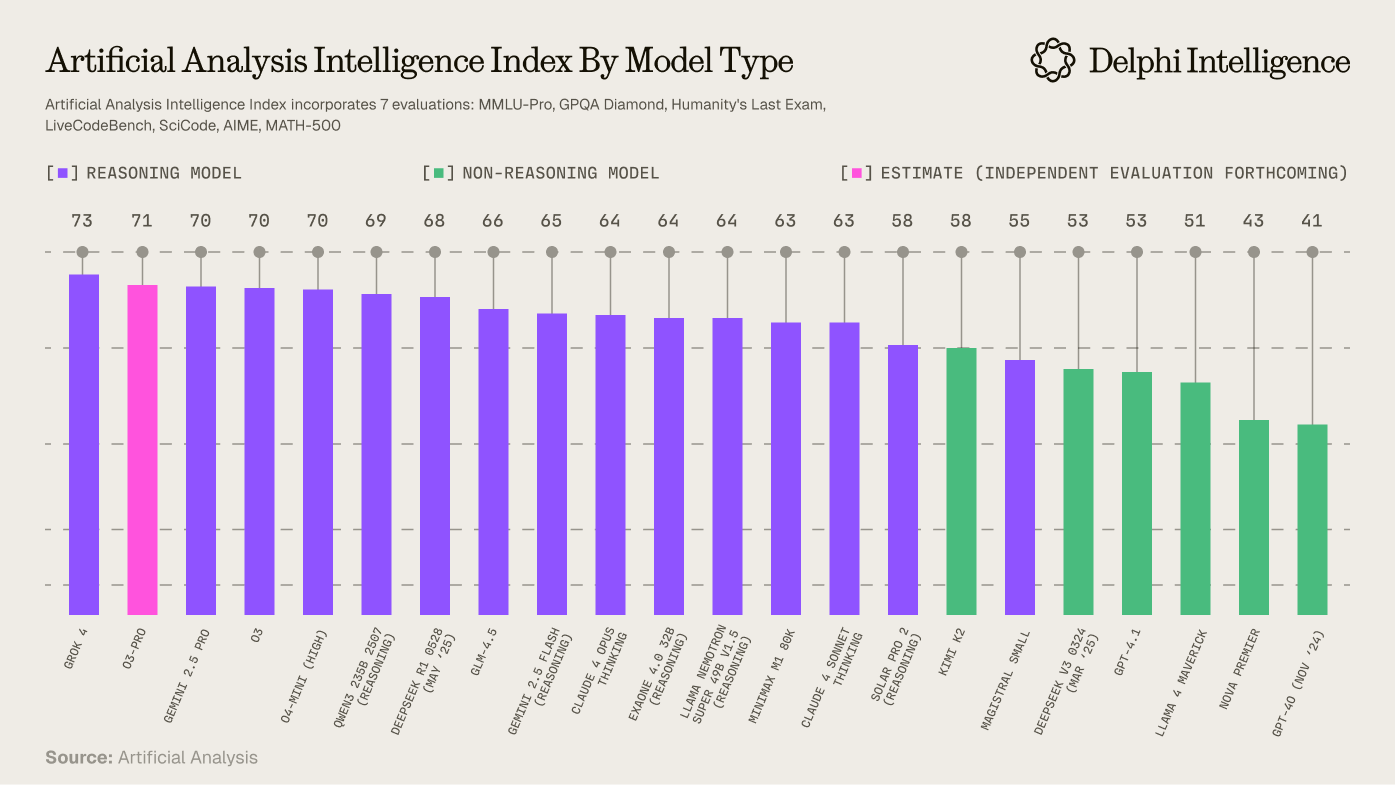
If pre-training is defined by vast amounts of data, then post-training depends on smaller, but higher-quality data sets. A key reason is the trade-off between compute and data quality in post-training: with higher quality data, labs can save substantially on compute, avoiding many inefficient reasoning traces when conducting reinforcement learning.
Reinforcement learning allows models to "learn" through trial-and-error via the outputs proximity to a specific reward signal. Environments with clear rules and signals (did you win?) like Chess or Go with fast feedback loops are ideal for implementing RL. Real world domains with verifiable answers - like math and coding - are also ripe. However, very few human tasks have such well-defined characteristics.
Domains without a clear, verifiable reward signal (i.e. the code failed to compile) tend to require human intervention. PhDs and other qualified data pipeline personnel are used to hone this process: crafting high-quality question-answer pairs, providing feedback on responses, and crafting rubrics that can be used by a "judge LLM" to grade synthetic outputs, for which the quantified score can be used as the reward signal, updating the weights accordingly.
Sourcing the right talent and maximizing the efficiency of this process is a big part of what leading data foundries now compete on.
Data Foundries: Inside the Sausage Factory
Meta just acquired a 49% stake in Scale for US$14b. Surge is raising >US$1b at ~US$15b. Mercor, Handshake, Turing, and Labelbox are seeing revenues and valuations going vertical on the back of lab spend.
Clearly these are not just "data labeling" commodity businesses, but what, exactly, is so difficult to replicate?
Scale AI's story is instructive, expanding from basic annotation to managing an entire "data supply chain" on behalf of the world's most important companies in their existential race for what is likely the largest TAM in technology's illustrious history.
The first rung of services still includes "core" functions around human data labeling. For example, annotating images with bounding boxes and classifications, transcribing and labeling audio, marking up text with entities or sentiment, etc.
The next rung would include RLHF: instilling the models with human preferences to make sure the knowledge is appropriately grounded.
Increasingly, however, the foundries are focused on data generation itself: both in sourcing rare tokens and the domain expertise needed to craft rubrics or RL environments to hone models for more complicated tasks.
On a recent podcast, LabelBox CEO Manu Sharma mentioned they are now conducting >2000 AI interviews everyday, an operational scale which can be hard to replicate.
These services are further complemented by workflow management platforms which allocate task assignments, reviews, annotation analytics, and more to help design the optimal data pipelines. These companies also provide sophisticated internal tooling to optimize labeling and compute budgets, zeroing in on the data that will actually move the needle in filling the gaps in model capabilities.
Lastly, data factories are rounding out their offerings with model evaluations and safety, providing red-teaming services to produce a closed feedback loop: crafting evaluations -> identifying issues -> and preemptively providing new training data to fix the issues, all while capturing meta data to make the process increasingly more efficient.
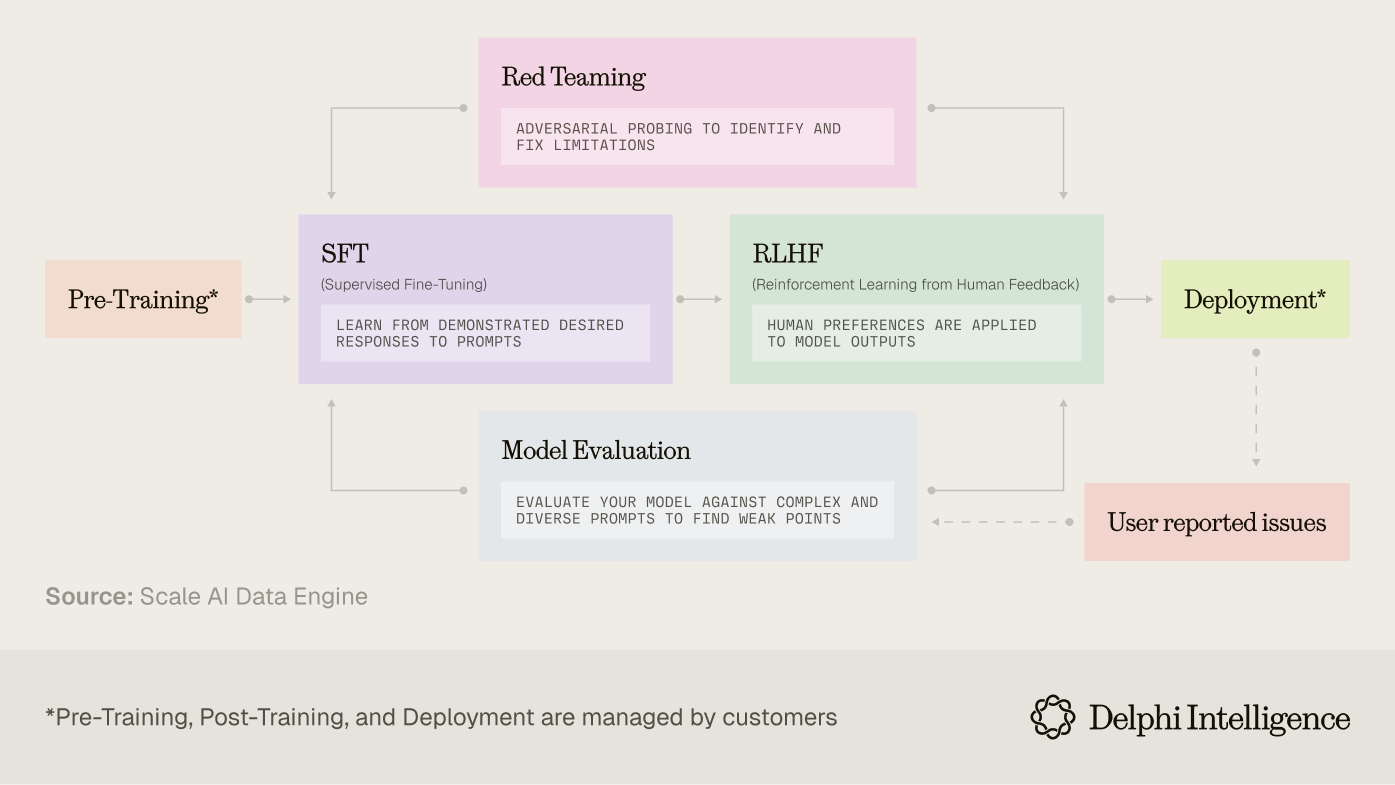
Far from being a commodity, the process itself can create a moat through:
- Operational scale and workforce mgmt: attracting and managing large distributed workforces including elite domain expertise. Ensuring high quality annotations consistently is hard, particularly as specialization increases. These are mission critical services making up what is a fairly small cost in the grand scheme of AGI capex.
- Tech infrastructure: service providers provide platforms with APIs, dashboards, cloud infra, ML assisted tooling... not to mention security and privacy controls - difficult for smaller players to replicate
- Data network effects: trust, integrations, and a growing customer base allow scaled players to leverage AI internally to optimize their own pipelines
The above is a generalization. In reality, different data vendors have different specializations. Scale AI is known for very large volume RLHF, Mercor for skilled talent acquisition, Mechanize for extremely detailed environments, etc. However, crossover is increasingly likely.
While demand for these services have been sky-rocketing, there are reasons for investors to remain cautious.
For one, the contracts appear to be quite short term and flexible in nature. Google's US$200m in expected spend with Scale AI was reallocated quickly after the acquisition by Meta. Other labs quickly followed. These are not long-term SaaS contracts with multi-year lock-ins. Labs are giving themselves plenty of flexibility, whether because they do not want to be beholden to a particular provider, or perhaps they believe they can automate some of these services over time.
However, Manu Sharma (LabelBox CEO) is quite confident that demand for his company's services will continue for some time. As both Andrej Karpathy and my colleague Lex have both pointed out, today's LLMs tend to be highly "jagged" in their intelligence. In most real world scenarios - even relatively basic examples (e.g. a call center) - the base model provides a fantastic starting point, but there are still so many edge cases which require an exceptionally rich data set to handle well. The context becomes essential.
In many ways, models are no longer bounded by IQ but by context. To continue thriving, data foundries will need to evolve, helping large labs and enterprises shift from the era of "prompt engineering" to "content engineering".

Context Engineering
Context engineering is moving beyond the art of prompt design to the science of optimizing information payloads for LLMs. The end goal is to break down valuable, complex human workflows into smaller steps, building architectures and systems of tool interactions, memory, and other context required to perform said tasks. To say this has been a budding area of research would be a dramatic understatement:
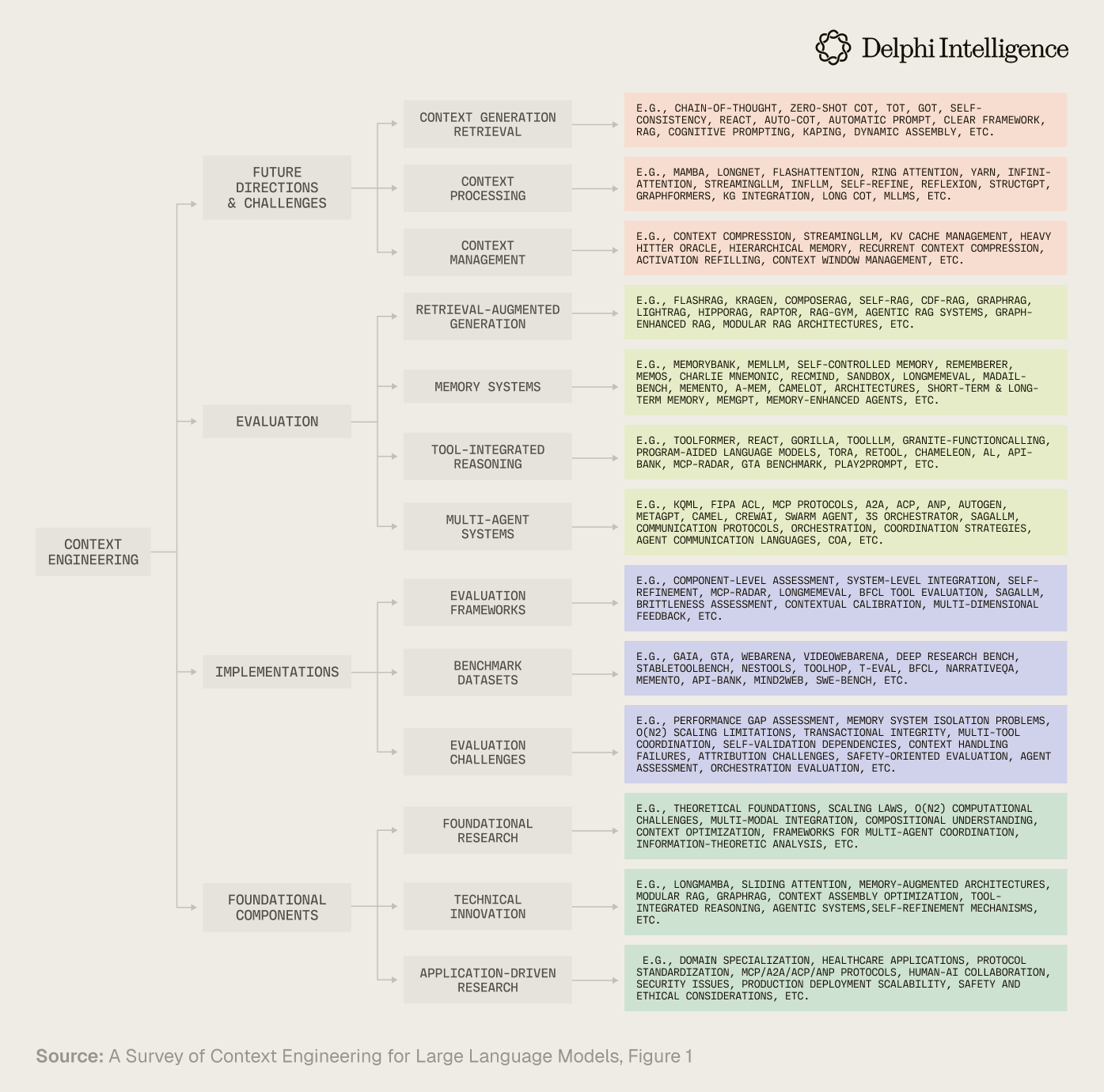
In this excellent survey, researchers from six elite universities synthesize the explosion of research across the various components which roll up into the emerging field of "context engineering." Below is my synthesis of the most relevant areas.

The foundational building blocks required to perform context engineering well and bridge LLMs to more complex applications include:
- Context retrieval and generation (encompassing prompt-based generation and external knowledge acquisition),
- Context processing (involving long sequence processing, self-refinement, and structured information integration)
- Context management (addressing memory hierarchies and compression techniques)

If context is the core bottleneck today, then scaling it becomes paramount to reach the next threshold of real world applications. In particular, context needs to be scaled across two vectors:
- Context Length Scaling: the computational and architectural challenges of processing ultra-long sequences (i.e. extending context windows from thousands to millions of tokens)
- Multimodal & Structural Scaling: scaling context beyond text to "encompass multi-dimensional, dynamic, cross-modal information structures" including temporal content, spatial context, cultural context etc.
LLMs tend to be biased towards text and can have difficulties with nuanced spatial and temporal reasoning like the location of an object or nuanced relationships in a video. Integrating context across various modalities - including text, videos, graphs, tool use, databases and more - remains challenging and expensive. We need to move beyond parameter scaling towards more complex systems which more closely mirror the nature of human intelligence.
To overcome this challenge, the big labs currently have a particularly voracious appetite all high-quality multimodal data sets.
Multimodal Demand
Interestingly, many massive and obvious pools of data are either:
- Legally off-limits or
- Not of high enough quality on which to train cutting edge models
For example, much of the available internet audio would not meet the Hertz / second threshold to be utilized in training by frontier labs. Or that YouTube Videos are often not bespoke enough or high resolution enough for particular niches that require high-precision spatial data.
Those data sets need to be generated, and the frontier labs are willing to pay handsomely at the moment.
In non-verifiable fields, particularly in those that are more extended in nature and require multimodal interaction, the odds of mistakes go up over time which compounds and wastes both time and compute. Human feedback in the loop can help save resources.
While the types of tasks which require RLHF will diminish over time, we are currently undergoing a multimodality data binge which seems likely to keep token hunters and data foundries busy for some time.
This is one of the reasons the AI Browsers Wars are expected to be so intense.
However, as the big labs overcome their limitations integrating multimodal reasoning tasks, the next logical step is taking context-engineering to the extreme: crafting virtual replica environments for reinforcement learning systems to train - much like AlphaGo - but for real-world tasks.
RL Environments
As Mechanize points out, we are undergoing a shift from data to software where "AI systems are best instructed by repeatedly having them interact with digital environments, attempt tasks, and learn from these outcomes."
Perhaps the simplest metaphor is a gym for models. A model can go into a specific environment and practice to develop new skills.
The challenge is that it's extremely difficult to craft environments that represent real human skills. Most human tasks are longer duration, require planning, multiple steps, and interacting with different tools and modalities. Performing RL on these longer-form agentic tasks becomes much more complicated.
"Where current methods are generating 10k-100k tokens per answer for math or code problems during training, the sort of problems people discuss applying next generation RL training to would be 1m - 100m tokens per answer. This involves wrapping multiple inference calls, prompts, and interactions with an environment within one episode that the policy is updated against"
-Nathan Lambert, Interconnects
A financial analyst is a good example. The tasks generally require very long context to:
- synthesize a bunch of information - like SEC filings, earnings transcripts, market sentiment, comparable valuations etc (which AI is pretty good at) but also
- continue on to build a model which forecasts what will happen next, a task that requires context, planning, and cross-domain reasoning, all with much sparser feedback.
This is a much harder lift.
Computer use models (Check out Can’s AI browser report!) are one of the most promising areas, yet routinely encounter blockers and pop-ups and the nuances of multimodal context.
Think of a sales rep who interacts across email, slack, voice calls, CRM data, google sheets etc. Simulating environments that replicate this complexity are very hard, and very manual.
But given the dollars at stake, it is also a very large opportunity.
Mechanize calls this “Replication Training” and expects a “GPT-3 moment for RL”
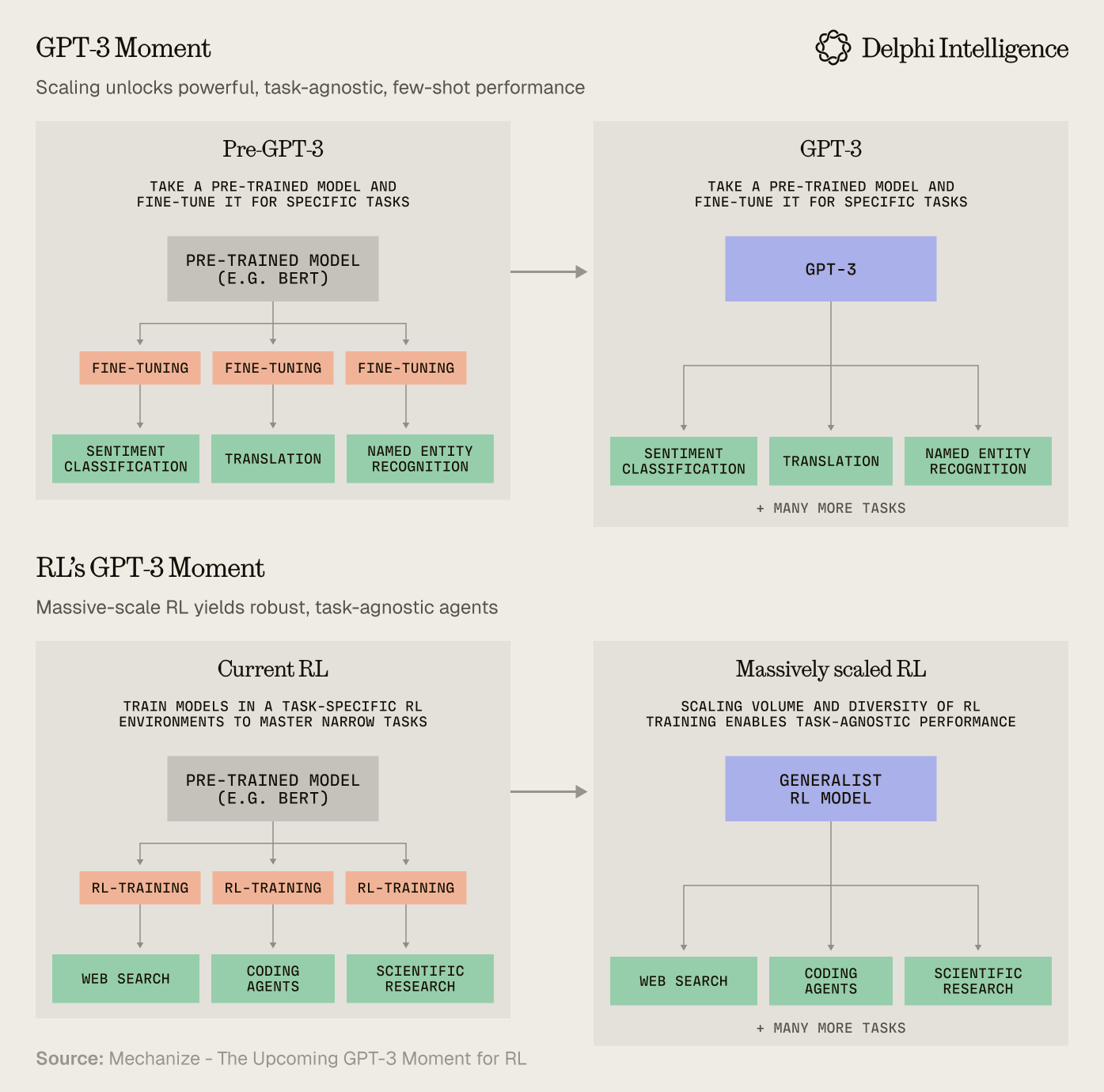
Replication training involves tasking AIs with duplicating existing software products, or specific features within them - starting simple but scaling up to more complex software like websites or professional software tools.
Recreating these environments will be labor intensive and require extremely comprehensive testing to replicate environments with high fidelity. However, generalizing RL is currently constrained by the limited volume of data and any out of distribution data is extremely valuable to the large labs, so even if hand-crafting environments does not seems very “bitter-lesson-pilled”, we should expect $ to flow handsomely given the relatively minor cost compared with the overall capex budgets.
In short, scaling RL across thousands of diverse environments may unlock meaningful generalization, providing many, many years of simulated task experience to automate workflows.
"We see huge potential in spending on environment compute instead of just RL compute. An example would be a highly realistic and difficult to reward hack environment using tens or hundreds of CPUs in tandem. This is an entirely new area ripe for scaling."
-Semianalysis: Scaling Reinforcement Learning
From RL Environments to World Models
In the post-training paradigm, we have seen fragmentation based on priorities between the big labs as they don't have infinite compute for infinite rollouts.
Anthropic is prioritizing coding: a bet that automated software development is a key component of AI research and therefore, the race to AGI.
OpenAI has leaned into their role as a consumer-facing platform aiming for brand and memory lock-in.
Google has an incredible number of data assets and consumer touchpoints, positioning them well as the personal assistant of choice. They also have a strong focus on basic science and scientific discovery.
xAI is leaning into its real time social feed and has privileged access to "real world" multimodal data sets.
The Chinese ecosystem's advantage is its open source compounding between leading labs, a strategy which appears to be more than making up for the dearth of compute.
While post-training priorities are diverging, one element in common is leveraging RL on the raw ingredients to conduct RL, making their flywheel even faster and more potent.
AlphaEvolve from DeepMind is perhaps the most interesting example: using RL loops to optimize chip design, data center scheduling, and enhance training and inference efficiency, all allowing for more reasoning traces with the same amount of compute.
While there is fragmentation in focus today, efforts seem likely to reconverge over time. The RL environment to rule them all: world models. As Demis mentions on Lex Fridman's podcast, these models would have digital twins of nearly every phenomenon and could simulate most interactions, continuously exploring and updating their weights accordingly.
Perhaps the bitter-lesson-pilled approach to RL will not be individual hand-crafted environments, but something much more all-encompassing…
With Genie 3 dropping just this week, DeepMind appears well on its way.
Continual Learning
While RL has plenty of runway, there are still limitations in today's LLMs. As Dwarkesh points out in an interview with Dario:
”What do you make of the fact that these things have basically the entire corpus of human knowledge memorized and they haven’t been able to make a single new connection that has led to a discovery?”
It’s an interesting question.
Gwern posits a potential solution: Daydreaming LLMs that use "spare" compute to search for novel connections between synthetic prompts, not too dissimilar from how the default mode network in a human brain churns consistently in the background before the Eureka moment spontaneously surfaces walking through the subway turn-style. Yet, the proposal still feels speculative and very cost-inefficient.
This begs the question though: without genuine insight, will models remain hemmed in by the frontiers of human knowledge in most messy, real-world domains? Perhaps LLMs can package the best of humanity and make it available at zero-marginal costs, but we may need fundamentally new architectures to make the leap from ubiquitous AGI to true ASI.
The promise of large virtual environments for RL is very promising, but Edwin Chen (CEO of Surge AI) is quite adamant that a host of tasks will continue to require human taste, especially in highly subjective areas, not to mention the numerous edge cases which are very hard for an environment builders to predict or model. This paradigm seems likely to continue requiring human feedback for some time to come, boding well for data foundry revenues.
However, RL is not the only game in town. As this survey points out, there are self-refinement and meta-learning approaches which aim for cyclical feedback mirroring techniques closer to human learning:
"Self-refinement enables LLMs to improve outputs through cyclical feedback mechanisms mirroring human revision processes, leveraging self-evaluation through conversational self-interaction via prompt engineering distinct from reinforcement learning approaches"
New techniques are popping up weekly:
With the right architectures, models may be able to continuously learn: generating and filtering their own training data to improve.
This could happen at the model layer or as part of a broader whole: multi-agent systems which interact bottoms up, more like a dynamic economy or biological system which builds in complexity over time as LLMs as agents specialize in using different tools and decompose tasks into manageable subtasks with fast feedback loops.

Interestingly, this appears to be what products like Grok 4 Heavy or Deep Research are already doing: dividing complex tasks up between different agents and synthesizing the responses into a single coherent whole. One could imagine this on a global scale, not limited to one mega-corp for orchestration and compute. Open Router is an early nod in this direction.
Perhaps the future will not be all powerful "world models" supplied by a few companies, but will involve billions of synthetic intelligences owned by individual developers and enterprises and other agents running on heterogeneous compute who make different tradeoffs and coordinate for optimal economic outcomes.
What if the end game of post-training, like its cousin pre-training, will require not just single companies hiring hosts of specialized data experts, but a harnessing of all of humanity?
In short, can the internet do for post-training what it did for pre-training?
The Internet: The Only Technology that Matters
Interestingly, one of the richest sources of data about what people want comes from... the products they use. Many companies may be able to avoid the expensive synthetic data generation process by already having the relevant data sets in house.
One could take this a step further: exploring the feedback loops between research and product, on a planetary scale.
"Going up one layer, the internet is an incredibly diverse source of supervision for our models and a representation of humanity. At first glance, many researchers might find it weird (or a distraction) that in order to make strides in research, we should turn to product. But actually I think it is quite natural: assuming that we care that AGI does something beneficial for humans and not just act intelligent in a vacuum (as AlphaZero does), then it makes sense to think about the form factor (product) that AGI takes on - and I think the co-design between research (pretraining) and product (internet) is beautiful"
-Kevin Lu: The Internet is the Only Technology that Matters
As this fantastic article points out, the internet has a number of advantages as an sandbox for RL:
1) The internet is highly diverse as anyone can add knowledge democratically. It is also pluralist in makeup, with no absolute truth (big win for one of my fav 20th century philosophers Isaiah Berlin).
"AI learns not from our best face, but from our complete face -- including arguments, confusions, and the messy process of collective sense-making"
2. The internet forms a natural curriculum for models to learn new skills given its global user base with varying degrees of expertise
"As we move towards RL, curriculum plays an even greater role: since the reward is sparse, it is imperative that the model understands the sub-skills required to solve the task once and achieve non-zero reward. Once the model discovers a nonzero reward once, it can then analyze what was successful and then try to replicate it again"
3. People want to use the internet.
>5 billion people currently use the internet. It is an fantastic indicator of what people want and is constantly infused with more data to provide incremental signal with changes over time
4. The internet is highly economical
People generally interact with the internet for free - whether to communicate, learn, or compete for status, these data sets are largely created for free as opposed to spending >US$1 billion dollars per year (and accelerating) to multiple vendors for synthetic data creation
We do not know exactly what form this will take, but the direction of travel makes a lot of sense. Instead of paying billions of dollars to data foundries to generate data, leveraging the natural advantages of real products delivered over the internet is the more strategic formula if the incentives are smartly crafted.
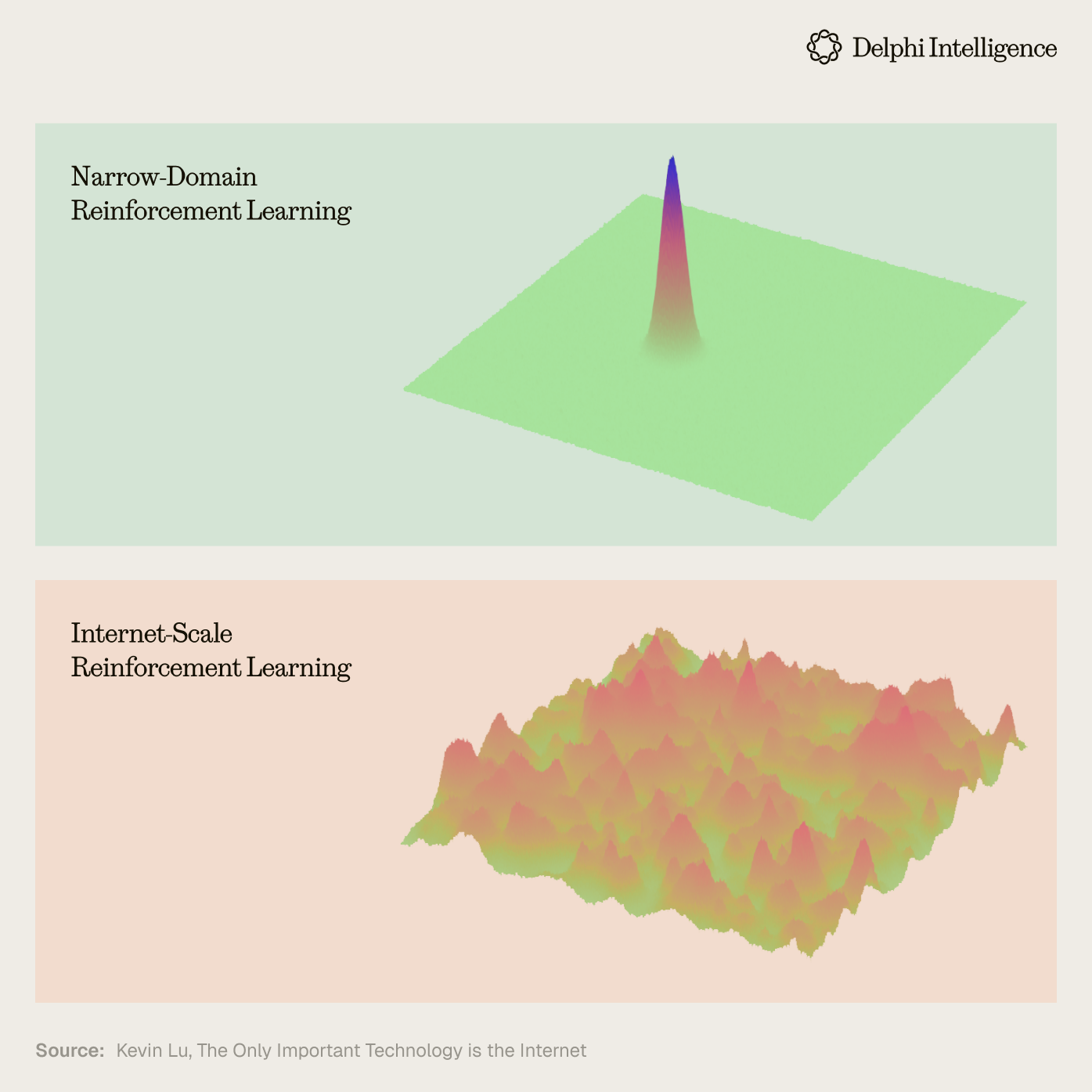
However, CEO of Surge AI, Edwin Chen is more skeptical. Open ended environments like Lmsys which tap human preferences can end up with very biased results, optimizing not for the elite but for the median slop. You need ways of filtering for taste and expertise while being attuned to pluralistic preferences in many domains.
In short, harnessing the internet has the potential to be transformative, but will take a lot of deep consideration to get right.
Coase for AI: Centralized vs. Composable Compute
While the internet has the potential to be an incredibly rich sandbox for post-training, the reality is that during the 2010s, much of the internet was siloed into a handful of tech giants running Ben Thompson's famed "aggregation" playbook and using the decade of artificially low rates, to build out compute oligopolies with the ensuing cashflow gushers they milked:

This is true in both AI ecosystems that matter: The US (with Google, Amazon, Meta, xAI, Microsoft, Apple) and China (Tencent, Baba, Bytedance, Meituan).
In reality, these ecosystems make up for a substantial portion of activity on the internet. An extremely valuable (and mostly private) asset on which to craft reinforcement learning loops.
Google is the most prominent example with an incredible array of data assets assembled and tracked for decades:
- Android
- YouTube
- Gmail
- Google Workspaces
- Google Maps
- Google Meets
- Google Calendar
- Google Pay
- Google Ads
- "Sign in with Google"
- Chrome
- etc

These assets where initially assembled for the purpose of selling evermore personalized ads, but seem increasingly (if properly integrated) primed to:
- Provide fantastic context for a personal assistant / 2nd brain
- Automate a host of human workflows
This powerful integration is not only happening at the product layer, but throughout the entire vertically integrated stack. Google has its own chips, it's own datacenters, its own networking fabric, its own orchestration software, its own mobile operating system, its own browser and its own applications.
In many ways, this echoes a question I confronted last year in DeAI III: Composable Compute when we explored integrated vs. modular tech stacks in AI:
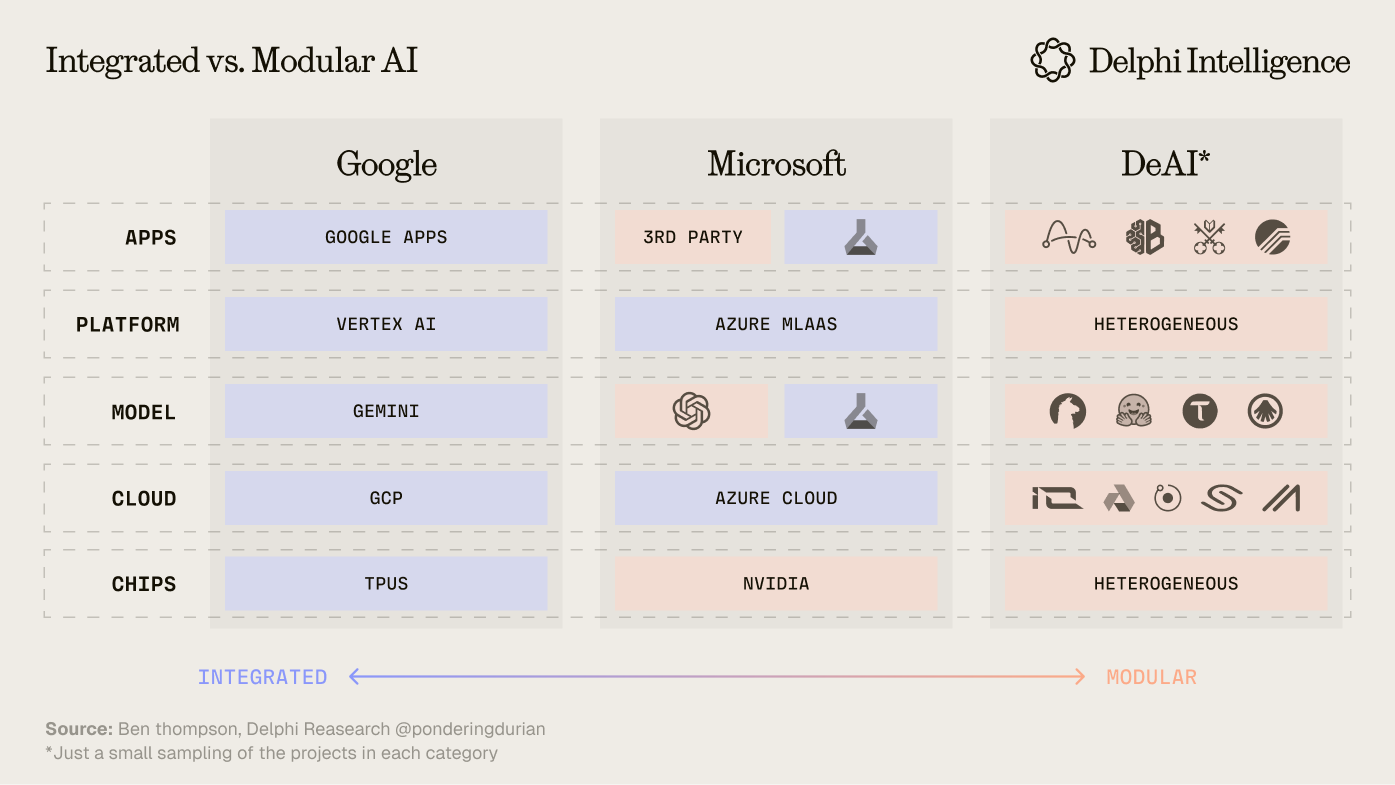
The question becomes: how quickly can Google optimize RL across its entire stack and product suite and - because it's integrated - will those loops ultimately outpace more modular, open source efforts which combine different chips, clouds, orchestration solutions, models, and end applications?
This is the bet the big labs are making. That a centrally organized mega-company, by aggregating talent, data, and compute, with tighter feedback loops, can beat the open internet in crafting synthetic intelligence.
To me, the answer seems likely to come down to some sort of "Coase's Theory of the Firm" for the AI Era: the breakdown in market share between the big labs and much more diverse multi-agent economies will be decided by this very question: do the benefits of low-cost latent compute at the infra layer, open source compounding at the model layer, and creativity at the application layer ultimately outweigh the costs of orchestration which the big labs mitigate by bringing everything under the roof of a single company?
Today, the balance of power still clearly stands with the mega-corps, but the shift to post-training does provide a nudge to more distributed approaches.
Cracks in the Armor
Compared with pre-training, post-training lends itself to more distributed infrastructure. The compute does not necessarily have to be co-located. Large labs are already working on multi-data center runs for continuous training.
Take this to its logical conclusion and you will find many of the most credible teams in DeAI - like Nous Research, Prime Intellect, Pluralis, Gensyn, and more - have been working on this very problem for years: orchestrating distributed, heterogenous compute in a trustless manner to provide the most cost-effective compute possible.
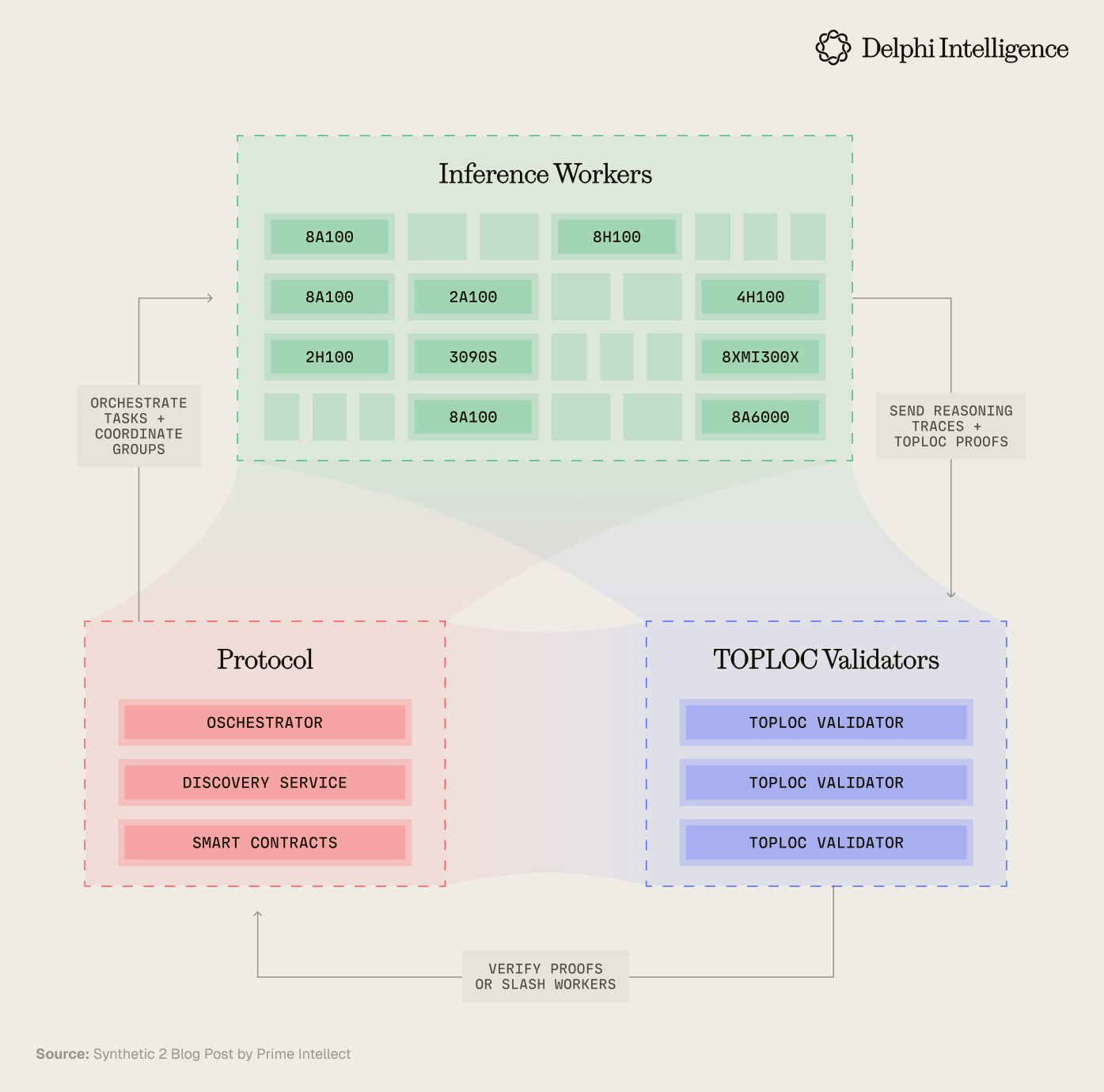
Low-bandwidth distributed training runs and RL swarms are already active, though they are still quite small relatively speaking.
On the data side, protocols like Grass and Oro may ultimately scale more effectively than centralized companies in sourcing private or increasingly "blocked" content. At scale, protocols can be permissionless, encourage global participation, and operate with less overhead. However, they are clearly more difficult to get off the ground and often suffer from poorer quality control given their decentralized nature.
These projects are still very early, but offer a peek into a potential path beyond the big tech oligopoly.
The Three-Fold Path
Based on the current trajectory, I see three broad paths forward.
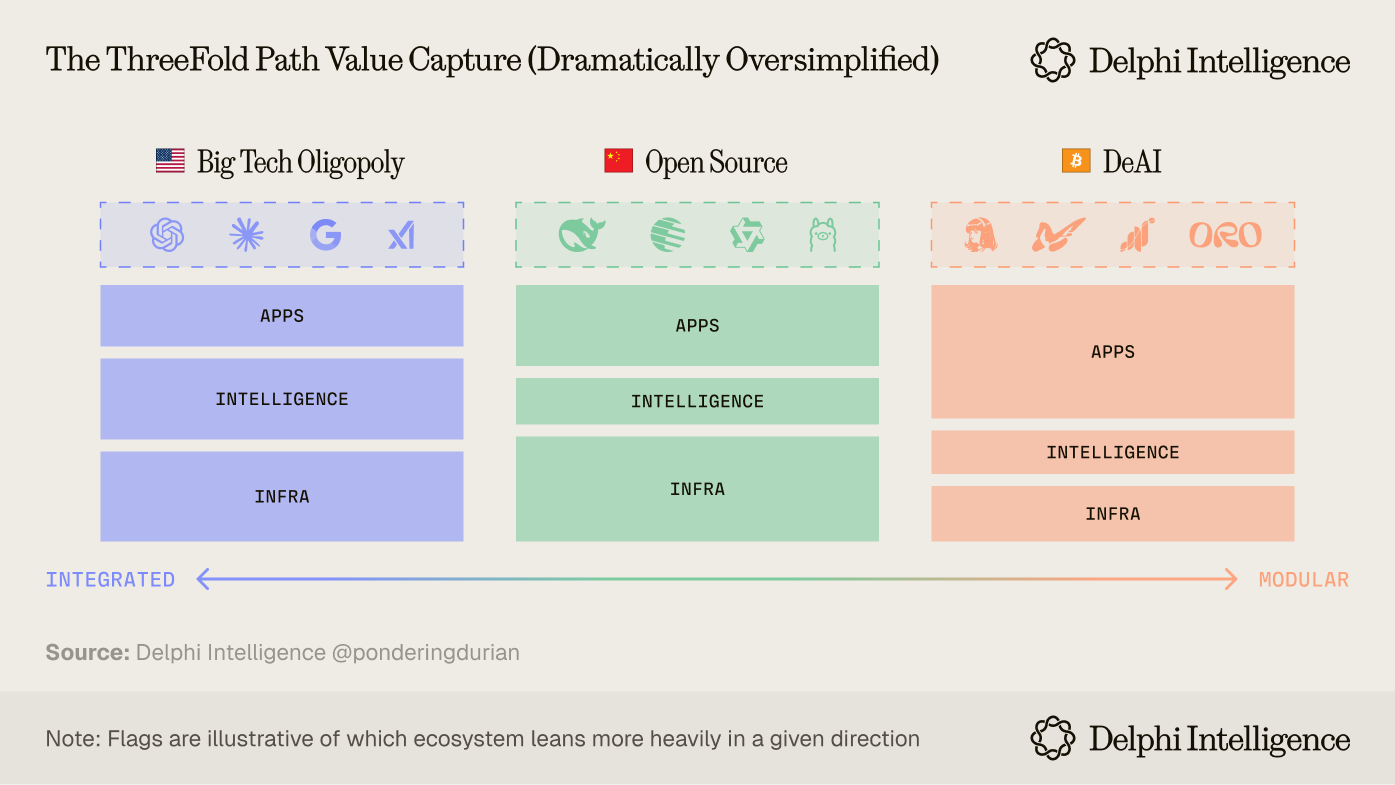
1) The Big Lab Intelligence Oligopoly (largely US led)
The US capitalist engine propels a handful of companies to stratospheric heights: allowing them to amass the data, compute, and talent necessary to reach "takeoff," ultimately renting their compute and intelligence to users, businesses, and the rest of the economy. Their shareholders get rich while everyone else stagnates, likely leading to political unrest which requires a new social contract.
2) Open Source Public Good (Yes, OSS from OAI cooked, but still largely China led)
An open source approach to AI development which either arrives via government mandate or open source compounding which commoditizes closed source models and restricts their investment appetite, pushing value accrual towards applications and infrastructure.
While Chinese lab results have been impressive, the shift to post-training combined with chip sanctions is a blow to China's open source efforts. Large US labs can tap their dominant, globally distributed data center footprint for continuous training, synthetic data creation and inference time compute - likely accelerating ahead based purely on compute.
Outside of a broad coordination of latent compute and talent, we are likely heading towards the big lab oligopoly.
3) Composable Compute
Open source talent combined with capitalist incentives somehow coordinates the world's latent compute, data, and talent to effectively implement "the China model" on a global scale. Compute providers and domain experts can receive proper compensation by joining open, permissionless networks.
Frankly, this is a long shot given the coordination overhead compared with the resources currently being marshalled by the big labs and the accelerating timelines to AGI / ASI.
Wen ASI?
To me, it seems very hard to divorce one's view of data foundries as an investable category with one's view of the timelines and the path to AGI / ASI.
Almost by definition, having humans in the loop (which is generally where most Data Foundries add value) is not ASI. On the other hand, after the system's capabilities exceed the need for human input, you have effectively arrived at a system which has surpassed the frontiers of human intelligence.
So... what is your timeline to AGI? To ASI?
The difference between the two has large implications for investing in data foundries.
The paradox here is that data will remain a key ingredient in the world's most important technological race. A race which is marshalling trillions in investment. If data (and talent) is a bottleneck (which it currently is), then the percentage of that total allocated to data will grow - both in the form of revenues or as generous takeout offers from labs and big tech companies to bring these strategic capabilities in house.
At the same time, if your timeline to ASI is ~5 years, do you really want to be paying 15x revenues for companies that would likely be made redundant at that time?
On the other hand, if we achieve ASI in that time frame, does it even matter?
Given the complexities of integrating multimodal data, the inability of LLMs (so far) to deliver novel insights, and the bottlenecks to performing RL on complex, extended, non-verifiable tasks, it seems likely that, based on the current paradigm, we will require humans in the loop for some time.
But paradigms can shift quickly. And the pace of AI's advance only appears to be accelerating.
So the logical question becomes: would you rather own the large data foundries... or just own the big labs and tech companies which seem inevitably poised to buy them or render them defunct?
Thank you to @overlyleveraged for his insights into multimodal data in this essay and to Luke and Lex for their feedback.
-@PonderingDurian, out









.png)
